Этот пост продолжает тему оценки качества алгоритмов машинного обучения для решения задач классификации. Рассмотрим кривые «полнота-точность», Gain, Lift, K-S (machine learning curves) и таблицу для анализа доходности. Самое главное — мы определим все кривые через уже знакомые нам понятия, часто используемые в ML (а не как обычно: для каждой кривой придумывается своя терминология).

Предыдущие посты в блоге на эту тему:
- Функционалы качества бинарной классификации
- AUC ROC
- Джини
- Логистическая функция ошибки
- Функции ошибок в задачах регрессии
Мы уже описывали ROC-кривую и рассматривали площадь под ней (AUC ROC). Сейчас опишем другие популярные кривые, которые строят для оценки качества классификации. Будем предполагать, что решается задача классификации с двумя классами: положительным (1) и отрицательным (0). Алгоритм выдаёт оценку принадлежности к классу 1, при выборе порога все объекты, оценки которых не ниже порога, мы относим к классу 1, соответственно, сразу становятся определены все метрики качества рассмотренные здесь: точность, полнота и т.п. Все кривые будем иллюстрировать на модельной задачи из этого поста с линейными плотностями.
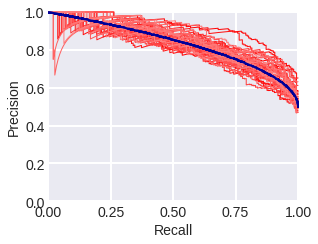
Кривая «полнота-точность». Как следует из названия, эта кривая строится в координатах полнота (R = recall) и точность (P = precision). На рис. 1-2 показаны PR-кривые в модельной задаче: синим – теоретическая кривая, красными тонкими линиями – кривые, построенные по выборкам с соответствующими плотностями. Рис. 1 – для выборок из 300 объектов, рис. 2 – для выборок из 3000 объектов. Заметим, что в общем случае PR-кривая не выпуклая. Площадь под ней часто используют в качестве метрики качества алгоритма. В нашей теоретической задаче PR-площадь равна 5/6=0.8(3) (попробуйте доказать), для выборок из 300 объектов после 100 экспериментов (генераций выборок) её оценка равна 0.839 ± 0.024 (std), для выборок из 3000 – 0.833 ± 0.012 (std).

Ниже представлен код для вычисления площади под PR-кривой.

На рис. 3 показано, как эмпирическая оценка площади PR-кривой зависит от объёма выборки при разной пропорции классов: когда классы равновероятны и когда есть дисбаланс классов. Более светлым коридором показаны стандартные отклонения от среднего. Видно, что для задачи с дисбалансом классов они больше.

Площадь под PR-кривой (AUC_PR) рекомендуют использовать как раз в задачах с дисбалансом классов, аргументируя это тем, что эта кривая точнее описывает правильность классификации объектов с большими оценками, тогда как ROC-кривая — различие распределений объектов разных классов по оценкам. Подумайте, корректна ли такая аргументация? Как быть с увеличением погрешности при оценке площади под PR-кривой в задачах с дисбалансом? Отдельно обращаем внимание, что при изменении баланса классов значение AUC_PR меняется, например, если мы случайную половину одного из классов удалим из выборки (AUC_ROC при этом практически не меняется), см. рис. 4.

Gain Curve (Chart) – это кривая в координатах «доля, отнесённых алгоритмом к классу 1», т.е. Positive Rate:

m — число объектов в выборке, и «какой процент класса 1 алгоритм отнес к позитивному», т.е. полнота для класса 1 или True Positive Rate:

Естественно, PR и TPR зависят от порога бинаризации, а сама кривая строится, когда порог пробегает всевозможные значения. Здесь есть несколько сюрпризов. Первый – из определения мы узнаём в этой кривой кривую Лоренца из машинного обучения, которую чаще называют Lift Curve (подробности можно почитать в этом замечательном посте). Кстати, здесь такой же график с небольшим изменением (по Y вместо TPR – TP) также назван «Lift-кривой», а здесь – CAP (Cumulative Accuracy Profile). Второй сюрприз в том, что дальше именем Lift Curve мы назовём другую кривую (а иногда называют и третью, но мы выбрали названия, которые согласовываются с наибольшим числом источников).
На рис. 5-7 показаны Gain-кривые в нашей модельной задаче: теоретические и (тонкими красными линиями) эмпирические, вычисленные по выборкам разных мощностей и при разном балансе классов.



На рис. 5-7 чёрной диагональю показана Gain-кривая для случайного алгоритма: понятно, что если алгоритм случайную долю PR всех объектов посчитал положительным классом, то мы ожидаем, что доля объектов класса 1, которых алгоритм посчитал положительными также будет TPR=PR. Чем выше расположена наша кривая относительно диагонали, тем лучше. Отношение высот Gain-кривой и диагонали часто изображают в виде кривой Lift Curve (Chart): она строится в координатах PR и TPR/PR. На рис. 8-10 показаны Lift-кривые, соответствующие нарисованным выше Gain-кривым.



В банковской среде приняты термины типа Gain-Top-10% или Lift-Top-10%, это просто значения TPR или TPR/PR, когда 10% объектов с наивысшими оценками алгоритма мы относим к классу 1 (т.е. при PR=0.1). Также почему-то принято строить эти кривые лишь по точкам PR = 0.1 (10%), 0.2 (20%), … 1.0 (100%), мы дальше покажем это в таблице.
Попробуйте вычислить площадь под Gain-кривой через AUC_ROC. По смыслу эта площадь — вероятность, что у случайного объекта из класса 1 оценка выше, чем у случайного объекта.
Построение Gain и LIft кривых логично в «задаче о предложении услуги»: мы контактируем с клиентами (обзваниваем или показываем баннеры и т.п.), выборка состоит из описаний клиентов, а целевой признак – отклик на предложение, тогда Gain-кривая показывает, как зависит покрытие целевой аудитории от масштаба контакта.
Kolomogorov-Smirnov (K-S) chart используется для сравнения распределений объектов класса 1 и 0 в пространстве PR (важно: а не оценок, которые выдаёт алгоритм). Строится две кривые: TPR(PR) и FPR(PR). Первая, кстати, знакомая нам Gain-кривая: доля объектов класса 1, которую алгоритм отнёс к классу 1 (в зависимости от процента объектов, которых алгоритм отнёс к классу 1). Смысл второй – доля объектов класса 0, которую алгоритм отнёс к классу 1. На рис. 11 показаны соответствующие кривые для модельной задачи в случае баланса и дисбаланса классов. Максимальная разница между кривыми часто называется KS-расстоянием. Интересно, что в модельной задаче TPR(θ), FPR(θ) не зависят от баланса классов, а вот K-S chart зависит… почему? Доказать, что при p1 = 0.1 на KSC максимальная разница TPR — FPR достигается в точке 0.3.


На рис. 13 видно, что K-S-расстояние может вычисляться с ошибкой, особенно на малых выборках. Подумайте, какому порогу бинаризации (каким свойствами он обладает) соответствует максимум TPR – FPR?

При анализе доходности (Profit Analysis) обычно используют такую таблицу: The Gains Table, для её построения объекты упорядочиваются по убыванию оценки принадлежности к классу 1, которую выдал алгоритм, потом разбиваются на 10 равных частей – децилей, каждому децилю соответствует строка таблицы.

- N – число объектов в дециле,
- % – процент объектов в дециле,
- cum_… – кумулятивное значение, например cum_% – сколько процентов объектов до этого дециля включительно,
- Prob – процент объектов из класса 1 в дециле,
- N_t – число объектов из класса t,
- %_t – какой процент объектов класса t попал в дециль,
- K-S – разница распределений по Колмогорову-Смирнову: cum_%1 – cum%_0,
- Lift – отношение cum_%1 / %.
По таблице можно посчитать экономику, связанную с задачей. Например, если таблица соответствует описанной выше задаче предложения услуги, стоимость контакта равна 1$, а доход с отклика равен 5$, тогда если проконтактировать с 10% клиентов, то траты = 11 238$, доход = 2572*5 = 12 860$, а прибыль = 1 622$.
Ссылки
Реализации функций отрисовки некоторых кривых можно найти здесь:

Добрый день Александр Геннадьевич! Спасибо за статью, очень интересная тема.
В европейских публикациях на тему банковского скоринга преобладает оценка качества моделей методом Колмогорова-Смирнова, а в Российских, Американских, Китайских, в основном AUC_ROC.
Какая метрика на ваш взгляд больше подходит для таких задач?
Связан ли выбор между этими двумя метриками с балансов классов?
Здравствуйте! Я думаю, что на практике K-S и AUC_ROC очень похожи, поэтому не имеет значение, что выбрать. Сам баланс не влияет на них. Проблема в другом: они измеряют различие распределений объектов разных классов на ответах алгоритма, а скоринге интересно другое… Банк может дать ограниченное число кредитов и на этом числе ему интересен риск. То, что исторически закрепились совсем нерелевантные метрики связано с тем, что они как раз не завязаны на объёмы кредитования и на риски, на которые конкретный банк может пойти. Поэтому вопрос «какой у вашей модели AUC_ROC/gini» вполне понятен.
Здравствуйте
А можете сказать ответ на вопрос в статье?
«Подумайте, корректна ли такая аргументация? Как быть с увеличением погрешности при оценке площади под PR-кривой в задачах с дисбалансом?»
Или дать какую-то подсказку?
Спасибо!
Здравствуйте! Тут второй вопрос подсказка к первому.
[…] Кривые в машинном обучении […]