Многие путаются в коэффициентах Джини, не понимают, что они бывают разные и для разных задач (и названия у них разные — просто в русском переводе, как всегда, многое схлопывается в один термин).
Есть коэффициент/индекс Джини (Gini coefficient), который используют при оценке качества классификации и регрессии. На русской странице Wiki не очень информативно, но вот на английской всё подробно: изначально это был статистический показатель степени расслоения общества данной страны или региона по отношению к какому-либо изучаемому признаку. Вычисляется как отношение площади фигуры, образованной кривой Лоренца и кривой равенства, к площади треугольника, образованного кривыми равенства и неравенства. Сейчас поясню.
Допустим, в компании работают 4 человека с суммарным доходом 8000$. Равномерное распределение дохода — это 2000$+2000$+2000$+2000$, неравномерное — 0$+0$+0$+8000$. А как оценить неравномерность, скажем, для случая 1000$+1000$+2000$+4000$? Упорядочим сотрудников по возрастанию дохода. Построим кривую (Лоренца) в координатах [процент населения, процент дохода этого населения] — идём по всем сотрудникам и откладывает точки. Для первого — [25%, 12.5%] — это сколько он составляет процентов от всего штата и сколько процентов составляет его доход, для первого и второго — [50%, 25%] — это сколько они составляют процентов и сколько процентов их доход, для первых трёх — [75%, 50%], для всех — [100%, 100%].
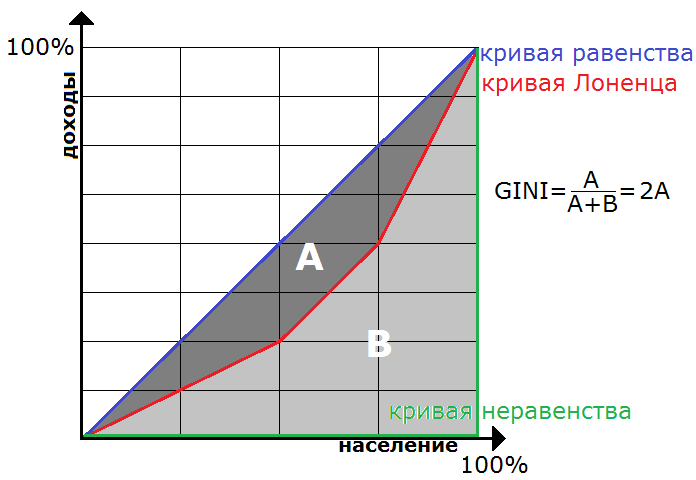
На. Рис. 1. построенная кривая Лоренца показана красным цветом. Кривая Лоренца, которая соответствует равномерному распределению дохода, — синяя диагональ (т.н. кривая равенства). Кривая Лоренца, которая соответствует неравномерному распределению, — зелёная (т.н. кривая неравенства). Вот площадь A, делённая на A+B=0.5, и есть коэффициент Gini.
При оценке качества классификации GINI = 2*AUCROC-1. Про AUCROC я уже как-то писал. Почему это они так связаны нигде подробно не описано. Я нашёл упоминание в работе Supervised Classification and AUC. Там всё логично: если в задаче классификации на два класса 0 и 1 интерпретировать эти числа как доходы. Но чтобы связь была именно GINI = 2*AUCROC-1, должно быть что-то типа рис. 2 (но ROC-кривая и кривая Лоренца это не одно и то же), кстати в презентации Credit Scoring and the Optimization concerning Area under the curve такая же картинка.

Есть ещё коэффициент/индекс Джини (Gini impurity), который используется в решающих деревьях при выборе расщепления. Я дал ссылку на английскую Wiki, поскольку русского аналога нет. Он тоже измеряет «равномерность», если p_i — частоты представителей разных классов в листе дерева, то коэффициент Джини для него равен
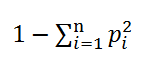
Только вот это другая равномерность, никак не связанная с рассмотренной ранее. Для первой нужно два показателя — доход и численность населения с таким доходом, а тут только проценты (частоты). В английской версии на странице Gini coefficient написано «не путать с Gini impurity» и наоборот.
Я не знаю, как лучше переводить impurity, скажем, С.П.Чистяков переводит как «загрязненность» (на мой взгляд, не очень звучит…).
Коррадо Джини (Corrado Gini, 1884), который всё это придумал был итальянским статистиком. Но кроме этого, он известный идеолог фашизмa, написал книгу «Научные основы фашизма». Прожил, кстати, довольно много — 80 лет, видимо, после войны не преследовался. Вот так бывает…

Александр, как Вам вариант перевода «неопределенность Джини»? Ещё можно пояснить теоретическую основу такой формулы коэф-та неопределенности Джини. Например, в англ версии статьи про деревья решений на википедии об этом говорится. https://en.m.wikipedia.org/wiki/Decision_tree_learning
Ещё хотелось бы задать вопрос про использование прироста информации или неопределенности Джини в деревьях и лесах. Сообщество Sklearn рекомендует для задач классификации использовать Джини (непонятно, почему, видимо, просто по опыту пришли к такому выводу). Или тут может быть такая подоплека, что неопределенность Джини напрямую связана с ROC AUC ( 2*AUC — 1), и тогда именно коэффициент неопределенности Джини предпочтителен для оценки обобщающей способности, если целевая метрика — AUC (или accuracy).
И кстати, есть ли какие-то теоретические основания «охотиться» за IG или Джини? Может, Вам известны работы, в которых показывается, что это приводит к минимизации ошибки обощения? Почему бы просто не максимизировать долю, если целевая метрика доля, логистическую ошибку, если она целевая и т.д? Все равно IG и Джини не монотонны и не антимонотонны, так что вычислительных преимуществ их использование не даёт.
«Неопределённость Джини», вроде, получше…
Если Вы про «Gini impurity is a measure of how often a randomly chosen element from the set would be incorrectly labeled if it were randomly labeled according to the distribution of labels in the subset»… ну это не совсем теоретическое обоснование, скорее, интерпретация. Хотя, возможно, стоит написать про это.
Я думаю, что gini impurity предпочитают просто исходя из опыта. Там, собственно, выбор небольшой: Джини или энтропия. Мы как-то делали опыт: в явном виде максимизировали целевые функционалы при разбиении, особого выигрыша это не даёт.
Никакой AUC gini impurity не максимизирует. Во-первых, Джини и энтропия, в принципе, не стремятся «к идеальному разбиению». Если внимательно посмотреть на критерии расщепления, то там есть слагаемое, которое отвечает за «лучше бить пополам». Во-вторых, Вы невнимательно прочитали пост. Gini coefficient = 2*AUCROC — 1, но gini impurity никак не связан с Gini coefficient и с AUCROC. Они вообще придуманы для разных задач!
Всю жизнь называл этот коэффициент неоднородностью Джинни)))) вот правда не знаю, кто вложил мне это в голову, боюсь что этот перевод я сам придумал, т.к. статей на русском про указанную метрику действительно было мало
Да, понятно, как раз попал под первую фразу поста. Спасибо за ответ!
Причем, что меня удивило, что многие преподаватели ШАДа не знают разницу между этими Джини… Выпускники, естественно, тем более.
Гораздо печальнее, что люди в ШАД &YDF не понимают (ну или как минимум не понимали в прошлом году, надеюсь в этом уже научились), как правильно «измерять» Gini, если в задаче большое perfomance window (период созревания), что в задачах кредитования, страхования или раннего предупреждения сбоев в сложных технических системах скорее норма, чем исключение. И не понимают, почему борьба за десятые доли Gini и менее в таких задачах не имеет смысла. Удивительного в этом ничего нет — ШАД имеет довольно узкую специализацию. Впрочем, в кредитовании, например, кроме периода созревания еще одна причина есть, почему за десятыми долями Gini гнаться не стоит.
То, о чем Вы пишите, конечно, печально, что у людей специальная эрудиция хромает и они термины путают, но это на результат работы особо не влияет. Опаснее другое — непонимание того, как та или иная метрика считаются, означает, что ты не понимаешь, когда она работать перестает и почему. Или как она на P&L влияет (такими исследованиями в России никто вообще не занимается на систематической основе)
ИМХО в России людей по пальцам можно пересчитать, которые понимают, почему точность и полнота (для оценки моделей классификации) хорошо работают в задачах планирования маркетинговых кампаний и плохо подходят для задач текущего кредитования, и почему там надо Джини использовать. Ну или почему, наоборот, Джини плохо работает, если у тебя выявление редких событий и какие метрики там надо использовать. Задача формально одна и та же — обычная задача классификации, а метрики надо использовать разные. Заказчик (обычный русский заказчик) просто не понимает, что ему требовать от аналитиков, а у аналитиков таких знаний тоже нет. В итоге и Джини (условно) отличный у модели, а денег она не приносит.
Кривая Лоренца, которая соответствует неравномерному распределению, — зелёная?
Да, там же написано: кривая Лоренца, которая соответствует неравномерному распределению, — зелёная (т.н. кривая неравенства).
При нечестном распределении зарплаты у 4х человек: 0+0+0+8000 получается, что
у 25% человек доход составляет 0%
у 50% — 0%
у 75% — 0%
у 100% — 100%.
Это как раз соответствует зелёному «уголку».
Подумал сейчас, что слова «равномерный/неравномерный», возможно, могут сбивать с толку. По простому, речь о честном распределении «всем поровну» и нечестном — «только одному».
Понял. Спасибо!
Возникла идея применить этот коэффициент для оценки состояния некой клиентской базы. Можно вместо зарплаты в примере про 4-х сотрудников использовать сумму дохода от клиента. Соответственно, мы получим метрику неравномерности клиентской базы, характеризующую устойчивость компании в случае потери части клиентов. При этом у части клиентов сумма дохода может быть отрицательной из-за того, что в сумме учитывается некие затраты на привлечение/удержание клиента. Можно ли как-то обобщить описанную методику расчета коэффициента на случай того, что некоторые величины будет отрицательными?
Ну, сходу можно придумать кучу эвристик: считать отрицательные значения нулями, прибавить ко всем доходам какое-то значение, чтобы все стали неотрицательными и т.п.
[…] соответствуют классическим критериям расщепления: Джини и энтропийному. Простой перебор поможет Вам выбрать, […]
[…] из не-интервьюшных стала прошлогодняя заметка Знакомьтесь, Джини (она хорошо гуглится по соответствующему запросу). На […]
Добрый день.
А что все-таки посоветуете использовать новичкам в области машинного обучения?
Индекс Джини или энтропию?
Как я понимаю индекс Джини удобней считается и чем он больше, тем лучше мы разбиваем предикторы на более мелкие, а если он очень низкий получается, то следовательно предиктор разбить невозможно.
У меня стоит задача в огромной выборке находить сильные отклонения от средних значений в системе с огромным количеством независимых переменных (предикторов).
Каждая независимая переменная количественная: по шкале от 0 до 15.
Верно ли я понимаю, что нужно разбивать каждую шкалу на все меньшие отрезки и каждый раз смотреть либо на индекс Джини, он должен быть как можно выше или на энтропию, она должна быть как можно ниже.
И как только Джини перестает расти, а начинает снижаться, мы перестаем разбивать выборку.
Но как быть с выборкой, ведь мы не можем бесконечно делить ее, в какой-то момент количество случаев станет слишком мало, и мы не сможем достоверно посчитать Джини и энтропию.
Заранее спасибо.
На практике разница между ними небольшая — используйте, что удобнее.
А задачу Вашу не совсем понял… у вас много объектов и признаков, каждый признак принимает значения {0,1,…,15}. Теперь что надо найти? И главное — зачем? Это случайно не обнаружение аномалий (anomaly detection) — когда мы определяем объекты, не похожие на других в выборке?
Вкратце задача такая.
Есть огромная база игр, где игроки играют по равновесной стратегии, она предполагает примерно определённые проценты блефа, например 60%.
Но есть узкоспециальные ситуации, это набор определённых действий или сочетание карт, когда все игроки будут сильно отклоняться от данной равновесной стратегии и процент блефа например станет 10 или 80%.
Наборы действий и параметров закодированы параметрами в базе данных, а зависимая переменная в задаче -это будет то насколько близко и точно мы угадываем данные отклонения .
Например если на обучающей выборке мы нашли 3 ситуации отклонения от равновесной стратегии :10,20 и 90, а на тестовой в тех же ситуациях оно стало 11,21 и 89- то это хороший прогноз, а если 40,50 и 60, то прогноз плохой, неустойчивый и мы просто подстроились под обучающую выборку.
В данной ситуации мы не можем сказать при каком наборе параметров мы получим данное отклонение от равновесной игры.
Допустим параметр от 0 до 5 кодирует количество карт одной масти , а от 0 до 12 -номинал карт. Если мы будем брать слишком мелкие отрезки например от 0 до 1 карты одной масти и от 0 до 1 карты , то будем получать слишком мелкие выборки, которые будут делать неустойчивый прогноз , а если возьмём слишком большой : от 0 до 5 одинаковых карт и номинал от 0 до 12- то получим большую выборку , но в ней потеряем все узкочпециалированные закономерности.
Собственно вопрос как отсюда извлечь все устойчивые закономерности ? Пока у меня идея использовать одновременно коэффициент Джини + чтобы выборка была по правилу Харрела, не менее 20 случаев на независимую переменную , в данном примере 2*20=40, не менее 40 случаев . Я верно рассуждаю?
Если Вы хотите найти простые интерпретируемые закономерности, то, видимо, да — правильно. Если же просто настроить модель, которая что-то предсказывает (процент блефа, например), то сейчас такие модели строятся без особой оглядки на «мелкость категорий при разбиении». Типичный пример — модель случайного леса (я тут в блоге писал про неё).
Спасибо.
Просто если мы получим например очень мелкую категорию из 15 случаев , которая будет 90% раз угадывать правильные ответы, то не будет ли высока вероятность подстройки данной категории под случайное совпадение? Или в случайном лесе и такие категории используются для реального прогноза. Насколько я понял глубина дерева как раз и используется для предотвращения такого рода мелких выборок. Но может оптимальней это делать ориентируясь на количество случаев в выборке?
Можно провести эксперимент… В одномерном случае код примерно такой:
from sklearn.ensemble import RandomForestRegressor
import pandas as pd
import numpy as np
cats = 5*[0] + 15*[1] + 30*[2] + 50*[3] + 100*[4]
testcats= [0, 1, 2, 3, 4]
target = np.random.randint(0, 2, 200)
XX = pd.DataFrame({‘cats’: cats, ‘target’: target})
cats = np.array(cats).reshape(-1, 1)
testcats = np.array(testcats).reshape(-1, 1)
from sklearn.preprocessing import OneHotEncoder
enc = OneHotEncoder()
enc.fit(cats)
X = enc.transform(cats)
X2 = enc.transform(testcats)
clf = RandomForestRegressor(n_estimators=100)
clf.fit(X, target)
print (‘случайный лес’, clf.predict(X2))
print (‘частоты’, XX.groupby(‘cats’).target.mean())
И здесь ответы примерно совпадают с частотами:
случайный лес [ 0.3606203 0.66127924 0.51196272 0.52716159 0.37366718]
частоты cats
0 0.400000
1 0.666667
2 0.533333
3 0.520000
4 0.370000
Если поиграться с параметрами и запретить строить листья с небольшим числом объектов, тогда ответ на мелких категориях будет смещаться в сторону среднего по всем мелким.
А вот если сделать многомерную задачу, то там лес сможет подхватывать закономерности по отдельным признакам… тут надо смотреть в конкретных задачах.
Но лес не панацея, можно и ридж-регрессию использовать (везде есть средства регуляризации, как раз для защиты от настройки на ненадёжные данные)
Спасибо, я сейчас поэкспериментирую и попозже напишу.
Любопытно, у меня тоже очень близкие значения получились.
А если образно описать мою задачу, то она будет выглядеть так.
Люди ходят в магазин за покупками, каждый покупает за один раз от 1 до 100 вещей, в среднем в районе 60 вещей, то есть выборка немного неравномерна.
У нас есть бесконечно огромная выборка разных порядковых переменных на этих людей:(десятки миллионов ситуаций)
Вес
Возраст
Доход
Дальность проживания
Количество детей
……
И так 25 параметров
И наша задача:
1) Находить только те группы людей, кто покупает как можно больше и как можно меньше, средние значения малоинтересно. (например более 70 вещей и менее 30 вещей)
2) Убеждаться что наше предсказание относительно количества покупок точное. Максимальная точность нам не нужна, допустим достаточно, чтобы точность угадывания была +-7 покупок, больше не обязательно. То есть, если мы предсказали у выбранной группы среднюю покупку >72, то значение может не более 79 и не менее 65 на тестовой выборке.
В данный момент я использую генетический перебор для того, чтобы комбинировать все варианты порядковых переменных и их диапазонов друг с другом и ставлю критерий выборки от 100 ситуаций для того, чтобы уменьшать вероятность случайные совпадения и большей точности прогноза.
Поэтому я и задал вам вопрос про выборку, так как точно я не знаю какое случаев необходимо взять для того, чтобы обеспечить заданную мной точность прогноза.
Вот любопытно как вы бы решали такую задачу с помощью машинного обучения? И подходит ли данная задача для него? Хочется потренироваться, но не знаю с чего лучше начать, так как целевая функция отличается от стандартных задач. Обычно для деревьев регрессии зависимая переменная — это число, а для деревьев классификации — это ответ Да/Нет.
Погодите, но у вас же тоже алгоритм выдаёт число (сколько товаров купит), просто функционал качества нестандартный: например, процент клиентов, на которых прогноз отличается от истины не более, чем на 7.
Да все верно — это число, но особенность в том, что мне нужно найти как можно больше таких групп людей, которые купят товаров больше значения x. И создать из них некий банк данных,чтобы потом этими данными пользоваться. Например предлагать промо-акции только людям из найденных групп, а не всем подряд.
Я ради интереса посчитал сколько будет занимать прямой перебор всех сочетаний переменных и их категорий при скорости запроса sql в 1 секунду. У меня получилось 120 лет. =)
Поэтому я задействовал генетический перебор, но хотелось бы освоить еще более современные методы поиска и оценки качества найденных решений, а заодно и потренироваться на интересной задаче, а не на теоретической.
То есть в простом варианте деревья регрессии подойдут?
А если не стремиться к определению именно групп людей? Просто: настраиваете регрессор, который по описанию человека предсказывает его объём покупки. Потом прогоняете этот регрессор на новых людях, ну и в зависимости от того много или мало купит принимаете действия (предложения промо и т.п.).
Спасибо попробую так.
Александр, здравствуйте!
Спасибо за статью, а можете ссылку на Credit Scoring and the Optimization concerning Area under the curve обновить? пытаюсь перейти, а там 404.
Спасибо. А презентация, действительно, исчезла… и я не могу найти её в интернете:(
[…] Знакомьтесь, Джини (5934) […]
[…] меня, а зачем ему помнить критерий расщепления Джини (Gini impurity)? Вряд ли на практике это […]
Александр, здравствуйте. Когда-то читал Вашу статью и спустя какое-то время вернулся к этой теме. Если интересно, здесь с доказательством формулы про линейную зависимость джини и AUC: https://habrahabr.ru/company/ods/blog/350440/
Здравствуйте, Дмитрий! Отличная работа! Всё очень подробно и чётко.
В формуле (4), видимо, надо написать gini=, а не AUC.
Да, gini, конечно. Спасибо за замечание!
[…] Знакомьтесь, Джини […]
[…] Джини […]
[…] Джини […]
[…] Знакомьтесь, Джини […]
Александр, добрый день! Возник вопрос к рисункам 1 и 2: я же правильно понимаю, что кривая Лоренца находится всегда под кривой «равенства»? Тогда почему на рисунке 2 красная линия (это ведь кривая Лоренца?) находится выше диагонали?
Тут это немного разные кривые — для разных задач (о доходах населения и классификации). Вот хорошая поясняющая работа: https://habr.com/ru/company/ods/blog/350440/