Этот пост продолжает серию про функции ошибки и функционалы качества в машинном обучении. Сейчас разберёмся с самой простой подтемой — как измерять качество чёткого ответа в задачах бинарной классификации. Уровень для чтения — начальный;)

Предыдущие посты в блоге на эту тему:
Рассматриваем задачу классификации на два класса (с метками 0 и 1), на рис. 1 показано её графическое представление.

Пусть классификатор выдаёт метку класса. Используем принятые в этом блоге обозначения: yi – метка i-го объекта, ai – ответ на этом объекте нашего алгоритма, m – число объектов в выборке.
Естественным, простым и распространённым функционалом качества является точность (Accuracy или Mean Consequential Error):

т.е. просто доля (процент) объектов, на которых алгоритм выдал правильные ответы. Недостаток такого функционала очевиден: он плох в случае дисбаланса классов, когда представителей одного из класса существенно больше, чем другого. В этом случае, с точки зрения точности, выгодно почти всегда выдавать метку самого популярного класса. Это может не согласовываться с логикой использования решения задачи. Например, в задаче детектирования очень редкой болезни алгоритм, который всех относит к классу «здоровые», на практике не нужен.
Рассмотрим т.н. матрицу несоответствий / ошибок (confusion matrix) – матрицу размера 2×2, ij-я позиция которой равна числу объектов i-го класса, которым алгоритм присвоил метку j-го класса.

На рис. 2 показана такая матрица для решения рис. 1, также показаны названия элементов матрицы. Два класса делятся на положительный (обычно метка 1) и отрицательный (обычно метка 0 или –1). Объекты, которые алгоритм относит к положительному классу, называются положительными (Positive), те из них, которые на самом деле принадлежат к этому классу – истинно положительными (True Positive), остальные – ложно положительными (False Positive). Аналогичная терминология есть для отрицательного (Negative) класса. Дальше используем естественные сокращения:
- TP = True Positive,
- TN = True Negative,
- FP = False Positive,
- FN = False Negative.
Замечание. Иногда матрицу ошибок изображают по-другому: в транспонированном виде (ответы алгоритма соответствуют строкам, а правильные метки – столбцам).
Замечание. Стандартная терминология немного нелогична: естественно называть положительными объектами объекты положительного класса, но здесь – объекты, отнесённые алгоритмом к положительному классу (т.е. это даже не свойство объектов, а алгоритма). Но в контексте употребления терминов «истинно положительный» и «ложно положительный» это уже кажется логичным.


Для точности (Accuracy) справедлива формула:

Ошибки классификатора делятся на две группы: первого и второго рода. В идеале (когда точность равна 100%) матрица несоответствий диагональная, ошибки вызывают отличие от нуля двух недиагональных элементов:
ошибка 1 рода (Type I Error) случается, когда объект ошибочно относится к положительному классу (= FP/m).
ошибка 2 рода (Type II Error) случается, когда объект ошибочно относится к отрицательному классу (= FN/m).
На заглавном рис. поста показаны известные шуточные иллюстрации ошибок 1 и 2 рода: ошибка 1 рода (слева) и ошибка 2 рода (справа). Когда я объясняю студентам, всегда привожу такой пример, который позволяет запомнить отличие ошибок 1 и 2 рода. Пусть студент приходит на экзамен. Если он учил и знает, то принадлежит классу с меткой 1, иначе — имеет метку 0 (вполне логично называть знающего студента «положительным»). Пусть экзаменатор выполняет роль классификатора: ставит зачёт (т.е. метку 1) или отправляет на пересдачу (метку 0). Самое желаемое для студента «не учил, но сдал» соответствует ошибке 1 рода, вторая возможная ошибка «учил, но не сдал» – 2 рода.
Через введённые выше обозначения выражаются следующие функции:
Полнота (Sensitivity, True Positive Rate, Recall, Hit Rate) отражает какой процент объектов положительного класса мы правильно классифицировали:

Здесь и далее показан числитель формулы (тёмно синим) и знаменатель (тёмно и светло синим). Слева это сделано для матрицы несоответствий, справа – для множеств: круглое – объекты положительного класса, квадратное – положительные объекты по мнению классификатора.
Точность (Precision, Positive Predictive Value) отражает какой процент положительных объектов (т.е. тех, что мы считаем положительными) правильно классифицирован:

Точность и полноту можно неформально называть «ортогональными критериями качества». Легко построить алгоритм со 100%-й полнотой: он все объекты относит к классу 1, но при этом точность может быть очень низкой. Нетрудно построить алгоритм с близкой к 100% точностью: он относит к классу 1 только те объекты, в которых уверен, при этом полнота может быть низкая.
Замечание. Отличайте «Accuracy» и «Precision». К сожалению, по-русски их называют одинаково «точность».
F1-мера (F1 score) является средним гармоническим точности и полноты, максимизация этого функционала приводит к одновременной максимизации этих двух «ортогональных критериев»:

Также рассматривают весовое среднее гармоническое точности (P) и полноты (R) – Fβ-меру (Fβ score):

Обратите внимание, что β здесь не вес в среднем гармоническом:

Почему используется среднее гармоническое понятно из рис. 4, на которых показаны линии уровня различных функций усреднения.

Видно, что линии уровня среднего гармонического сильно похожи на «уголки», т.е. на линии функции min, что вынуждает при максимизации функционала сильнее «тянуть вверх» меньшее значение. Если, например, точность очень мала, то увеличение полноты, пусть и в два раза, не сильно меняет значение функционала. Нагляднее это показано на рис. 5: при точности 10% F1-мера не может быть больше 20%.

При использовании Fβ-меры линии уровня «перекашиваются», один из критериев (точность или полнота) становится важнее при оптимизации, см. рис. 6.

Из функционалов качества, которые получаются из матрицы несоответствий, можно также отметить специфичность (Specificity) или TNR – True Negative Rate:

т.е. процент правильно классифицированных объектов негативного класса. Полноту иногда называют чувствительностью (Sensitivity) и используют в паре со специфичностью для оценки качества, также часто их усредняют (об этом поговорим дальше). Оба функционала имеют смысл «процент правильно классифицируемых объектов одного из класса». Можно ввести понятие полноты Rk для k-го класса: это полнота, если считать класс k положительным, тогда

Также запомним False Positive Rate (FPR, fall-out, false alarm rate):

– доля объектов негативного класса, которых мы ошибочно отнесли к положительному (это нужно для понимания функционала AUC ROC).
Коэффициент Мэттьюса (MCC – Matthews correlation coefficient) равен
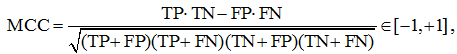
его рекомендуют применять для несбалансированных выборок. Давайте разберёмся, что означает эта «сложная формула». Рассмотрим среднее геометрическое точности и полноты:

Теперь возьмём среднее геометрическое точности и полноты класса 0 (т.е. считая это класс положительным), перемножив эти средние геометрические, получим

Логично полученное выражение максимизировать, по аналогии можно выписать выражение для минимизации. Если теперь внимательно посмотреть на формулу MCC, то становится понятным, что она означает и почему её значение лежит на отрезке [–1, +1] (оставляем это как задание читателю).
Каппа Коэна (Cohen’s Kappa)
В задачах классификации часто используют функционал качества Каппа Коэна (Cohen’s Kappa). Его идея довольно простая: поскольку использование точности (Accuracy) вызывает сомнение в задачах с сильном дисбалансом классов, надо её значения немного перенормировать. Делается это с помощью статистики chance adjusted index: мы точность нашего решения (Accuracy) пронормируем с помощью точности, которую можно было получить случайно (Accuracychance). Под случайной здесь понимаем точность решения, которое получено из нашего случайной перестановкой ответов.

здесь красным выделена вероятность угадать класс 0, а синим – класс 1. Действительно, класс k угадывается, если алгоритм выдаёт метку k и объект действительно принадлежит этому классу. Предполагаем, что это независимые события (мы же хотим вычислить случайную точность). Вероятность принадлежности к классу k можно оценить по матрице несоответствий как долю объектов класса k. Аналогично, вероятность выдать метку оцениваем как долю таких меток в ответах построенного алгоритма.
Сбалансированная точность (Balanced Accuracy)
В случае дисбаланса классов есть специальный аналог точности – сбалансированная точность:

Для простоты запоминания – это среднее полноты всех классов (мы ещё вернёмся к этому определению), ну или в других терминах: среднее чувствительности (Sensitivity) и специфичности (Specificity). Отметим, что чувствительность и специфичность тоже, неформально говоря, «ортогональные критерии». Легко сделать специфичность 100%-й, отнеся все объекты к классу 0, при этом будет 0%-я чувствительность, и наоборот, если отнести все объекты к классу 1, то будет 0%-я специфичность и 100%-я чувствительность.
Если в бинарной задаче классификации представителей двух классов примерно поровну, то TP + FN ≈ TN + FP ≈ m/2 и сбалансированная точность примерно равна точности обычной (Accuracy).
Все указанные функционалы реализованы в библиотеке scikit-learn:

Сравнение функционалов
Рассмотрим модельную задачу, в которой плотности распределения классов на оценках, порождённых алгоритмом, линейные, см. рис. 7 (алгоритм выдаёт оценки принадлежности к классу 1 из отрезка [0, 1], именно на этом отрезке они линейные). На рис. 7 показана конечная небольшая выборка, которая соответствует изображённым плотностям, мы же будем считать, что выборка бесконечная, поскольку плотности простые и позволяют в явном виде вычислить функционалы качества даже в случае такой бесконечной выборки. Будем считать, что классы равновероятны, т.е. наша бесконечная выборка сбалансирована. Выбранная задача очень удобна для исследования и уже использовалась при анализе функционала AUC ROC.

Заметим, что подобные распределения возникают в задаче, показанной на рис. 8 (объекты лежат внутри квадрата [0, 1]×[0, 1], два класса разделяются диагональю квадрата), если алгоритм в качестве оценки выдаст значения первого признака.

Изобразив плотности немного по-другому, мы в явном виде можем вычислить элементы матрицы несоответствий при конкретном пороге бинаризации, см. рис. 9. Все они пропорциональны площадям выделенных зон (обратите внимание на масштаб осей):


Теперь можно вывести формулы для рассмотренных функционалов качества как функции от порога бинаризации:

Попробуйте вывести эти формулы сами, кроме того, попробуйте определить пороги бинаризации при которых указанные функционалы максимальны (здесь будет один сюрприз).
Возникает естественный вопрос: на практике у нас нет бесконечных выборок, что изменится, если мы вычислим значения функционалов на конечной, объекты которой сгенерированы в соответствии с указанными распределениями? Частично ответ на этот вопрос показан на рис. 10. Как видно, кривые довольно близки к теоретическим при m=300, при увеличении выборки в 10 раз практически совпадают.

Рассмотрим теперь графики наших функционалов качества как функций от порога бинаризации, см. рис. 11. Заметим, что кроме F1-меры все они симметричны относительно порога 0.5, но это вполне логично. Теперь рассмотрим ситуацию неравновероятных классов, т.е. когда выборка несбалансированна. На рис. 12 показаны графики функционалов в случае, когда класс 1 в два раза чаще встречается в выборке, чем класс 0. Обратите внимание, что все графики стали несимметричными, кроме графика сбалансированной точности – эта функция не зависит от пропорций классов!


Вопросы для самопроверки
В конце серия вопросов с подвохом… если Вы хотите кого-нибудь «завалить» по простой теме «оценка качества в задачах бинарной классификации», то непременно задайте их:
- у какого функционала качества самый маленький оптимальный порог бинаризации в общем случае, почему? Для справки: ответ «у F1-меры» в общем случае неверный (можно даже простой пример привести).
- какой функционал качества действительно имеет смысл использовать в задачах с сильным дисбалансом классов (заметим, что стандартные советы: BA, MCC, κ, F1 обладают совершенно разными свойствами)?
- какой «самый неустойчивый» из перечисленных функционалов (его значения на небольших выборках сильнее отличаются от вычисленных на достаточно больших)?
- что изменится в примерах выше, если от линейных плотностей перейти к нормальным? Как это сделать корректно (и в чём некорректность описанной модельной задачи)?
- верно ли, что максимальное значение точности (т.е. значение точности при оптимальном выборе порога) всегда не меньше максимального значения сбалансированной точности?
Что дальше…
По задачам классификации осталось рассказать про все скоринговые функции оценки качества в задачах бинарной классификации, про AUC ROC и LogLoss уже было. А потом — как все рассмотренные функционалы обобщаются на случай многих классов. Соответствующие посты скоро будут.
Традиционное в последнее время видео к материалу поста я залью чуть позже.
На правах рекламы
С сентября чему-то научиться у автора блога можно в этом замечательном проекте: Ozon Masters. Кроме курса по машинному обучению, будет много других с потрясающими преподавателями: Андрей Соболевский, Иван Оселедец, Павел Клеменков, Юрий Дорн, Александр Дайняк.

Недавно было соревнование по ML с бинарной классификацией и метрикой f1 macro. С ROC AUC более-менее понятно, а вот как правильно минимизировать f1? Я минимизировал logloss, а потом искал порог для предсказанной для тренировочного набора данных вероятности, чтобы f1 было минимально.
Можно делать, как делали Вы. Правильно только сделать отдельный валидационный набор данных, и на нём подобрать порог. Можно это совместить с ансамблированием: строить разные модели, потом их ответы rank-нормировать, брать линейную комбинацию и определять порог бинаризации. Тут уже параметров больше: коэффициенты и порог. Есть также разные работы, где показано, как оптимизировать F-меру напрямую:
Нажмите для доступа к eban17a.pdf
Нажмите для доступа к 1206.4625.pdf
Можно ещё сделать такую хитрость: перебирать разные loss-функции и посмотреть, при использовании какой получается максимальная F-мера.
Добрый день,
мне метрики семейства accuracy (в т.ч. Balanced Accuracy и Каппа Коэна) кажутся более «справедливыми». Есть ли подобные статьи (про непосредственно их оптимизацию) для этого семейства метрик?
Да, кое-что можно загуглить. Но их оптимизировать можно и просто подбором порога бинаризации.
Скажите, пожалуйста, почему при добавлении перемешанного столбца могут расти метрики качества на тестовой выборке (которую при обучении никак не использовали)? Ведь по логике это «белый шум» и при переобучении результат на тестовой выборке должен быть только отрицательным, а без переобучения- нулевым.
Они наверное незначительно растут? В пределах погрешности.
Скажите, пожалуйста, какая правильная стратегия подбора пенальти (L2)? Я попробовал варьировать множитель L2 и смотрел на изменения метрик MCC и коэффициента Каппа Коэна (у меня сильно несбалансированная выборка). Получилось, что в некоторых случаях эти метрики достигают максимума при разных пенальти (отличие в 10 раз), а иногда у метрик даже нет никакого максимума (только ухудшение, по сравнению с отсутствием пенальти). Как вы это делаете?
Александр, спасибо за отличный структурированный обзор!
Возникла пара вопросов:
1. В примере про студента: «Если он учил и знает, то принадлежит классу с меткой 1, иначе — имеет метку 2 (вполне логично называть знающего студента «положительным»).»
наверное, имеется ввиду «иначе — имеет метку 0»?
2. Про этот же пример — обычно ошибки 1-го и 2-го рода имеют семантику «ложная тревога» и «пропуск цели», соответственно. В таком контексте, возможно, стоит поменять классы местами. Т.е. профессор выступит в роли «злобного классификатора», цель которого — выявить нерадивых студентов (0 — зачёт, 1 — пересдача). В таком случае, ошибка 1-го рода (ложная тревога) — это «учил, но не сдал», а ошибка 2-го рода (пропуск цели) — «не учил, но сдал». Выглядит, на мой взгляд, вполне органично, пусть и более негативно 🙂
1: Да, Вы правы. Сейчас поправлю.
2: Можно, но, вроде, в текущих обозначениях тоже нормально интерпретируется. Экзаментор ищет знающих студентов. Пропуск цели — пропустил знающего, ложная тревога — объявил всем, что нашёл, но ошибся…
Спасибо за внимательность!
Кстати, интересно, есть ли в природе какие-то рекомендации, что обозначать за классы 0 и 1 в бинарной классификации. Возможно, в медицинской статистике есть какая-то сложившаяся практика — у них очень часто сильный дисбаланс классов бывает.
С точки зрения моделей алгоритмов машинного обучения — нет никакой разницы. С точки зрения функционалов качества она есть, но как написано в заметке, полноту и точность можно вводить для класса 0 и 1. Просто по умолчанию вводят для 1. Поэтому основная рекомендация здесь — чтобы была верная интерпретация. Как правило, это совпадает с тем, что «самый маленький класс» обозначают за 1. Например, редкую болезнь. Тогда полнота — какой процент заболевших мы нашли, точность — какой процент из найденных заболевшие.
Здравствуйте Александр Геннадьевич. Есть ли у вас история из практики: когда стоит применять MCC, когда — среднее геометрическое точности и полноты, когда — f1? Из графиков явно следует, что они устойчивы к дисбалансу. Но почему можно отдать предпочтение той или иной метрике в бизнес-кейсе, не ясно.
По поводу выбора оценки для бинарной классификации: посмотрите статьи Davide Chicco
https://scholar.google.com/citations?hl=en&user=x9ukpr0AAAAJ&view_op=list_works&sortby=pubdate,
он доказывает, что MCC лучше всех. Я в своей сравнительной статье бинарных оценок показал, что все известные оценки или не инвариантны к дисбалансу, или совпадают со сбалансированной точность. См. Сравнительный анализ оценок качества бинарной классификации, 2020.
Ещё, по поводу каппы. Вы пишите, что мы считаем вероятность угадать, что объект относится к классу k. Но в каппе считается что-то ещё.
Нужно найти все события, которые благоприятствуют угалываниям. Иными словами, мы хотим взять случаи, когда y=k и a=k. Тогда:
m00/m + m11/m
Да, это не каппа. Но, кажется, что это то, что описано в статье словами. Кажется, каппа это что-то более сложное, ибо там есть какие-то перемножения вероятностей.
Возможно, я где-то ошибся. Но ошибки не вижу. Поправьте, если она есть
Спасибо за статью. Не могли бы вы поделиться кодом для генерации выборки модельной задачи?
def make_test(n = 100, p=0.5, seed=10):
«»»
Подготовить данные модельной задачи
«»»
np.random.seed(seed)
x = np.random.rand(n)
y = np.random.rand(n)
z = (np.random.rand(n) 0:
x[i], y[i] = np.max([x[i], y[i]]), np.min([x[i], y[i]])
else:
x[i], y[i] = np.min([x[i], y[i]]), np.max([x[i], y[i]])
data = pd.DataFrame({‘x’: x, ‘y’: y, ‘z’: z})
return (data)
[…] Функционалы качества бинарной классификации […]
[…] Функционалы качества бинарной классификации (4649) […]
Александр, а можно добавить ответы на «вопросы для самопроверки»?
Пока не буду этого делать.
[…] Функционалы качества бинарной классификации […]
Добрый день, Александр Генадиевич. Возможно, будет интересна недавняя статья на эту тему:https://www.sciencedirect.com/science/article/pii/S0031320319300950 (The impact of class imbalance in classification performance metrics based on the binary confusion matrix)
Спасибо за ссылку!
[…] в третьем знаке после запятой). Если используется F1-мера, то тут уже интереснее – подобные функции ниже и […]
Спасибо за интересную статью.
Заметил, что под рисунком 12 (кстати, вместо «рис.12» написано второй раз «рис.11») указано «класс 1 в два раза вероятнее класса 0». То же самое утверждается и в тексте. А не наоборот, случайно? Ведь если посмотреть на график «Acuracy», то он при нулевом пороге имеет значение 1/3, но если отсчетов класса «1» в два раза больше чем «0», то Accuracy должно быть равно 2/3.
Да, Вы правы.
повеселило
Здравствуйте!
А будут опубликован ответы (желательно с решениями!) к финальным вопросам?
Вот моя, скорее всего неудачная, попытка:
1) Кажется, что при theta=0 R будет максимальной, т.е. 1.
Наверное потому, что ф-ия 1 — theta^2 убывающая.
2)Тут выбор между BA,F1,MCC: из текста следует, что BA лучше т.к.
инвариантен имбалансу в данных. На практике вроде исп. F1 или MCC.
В общем надо использовать ту метрику, где задействованы все 4 категории — TP,TN,FP,FN.
Остановлюсь на BA, хотя скорее всего правильный ответ MCC. Но как корректоно обосновать
я не знаю.
3)Провел численный эксперимент и вроде бы получил, что MCC самый неустойчивый.
Каппу не рассматривал, т.к. не до конца понял как ее эмпирически считать…
4)Да вроде ничего не должно измениться, только грамотно перемасштабировать.
Если правильно понял вопрос, то в описанной модели TP+TN+FP+FN != 1.
5)Кажется что да, верно.
Надеюсь хоть что-то правильно…
PS: Последний рисунок подписан неверно — Рис. 12.