Стекинг (Stacked Generalization или Stacking) — один из самых популярных способов ансамблирования алгоритмов, т.е. использования нескольких алгоритмов для решения одной задачи машинного обучения. Пожалуй, он замечателен уже тем, что постоянно переизобретается новыми любителями анализа данных. Это вполне естественно, его идея лежит на поверхности. Известно, что если обучить несколько разных алгоритмов, то в задаче регрессии их среднее, а в задаче классификации — голосование по большинству, часто превосходят по качеству все эти алгоритмы. Возникает вопрос: почему, собственно, использовать для ансамблирования такие простые операции как усреднение или голосование? Можно же ансамблироование доверить очередному алгоритму (т.н. «метаалгоритму») машинного обучения.

Простейшая схема стекинга — блендинг (Blending): обучающую выборку делят на две части. На первой обучают базовые алгоритмы. Затем получают их ответы на второй части и на тестовой выборке. Понятно, что ответ каждого алгоритма можно рассматривать как новый признак (т.н. «метапризнак»). На метапризнаках второй части обучения настраивают метаалгоритм. Затем запускают его на метапризнаках теста и получают ответ.

Самый большой недостаток блендинга (в описанной реализации) — деление обучающей выборки. Получается, что ни базовые алгоритмы, ни метаалгоритм не используют всего объёма обучения (каждый — только свой кусочек). Понятно, что для повышения качества надо усреднить несколько блендингов с разными разбиениями обучения. Вместо усреднения иногда конкатенируют обучающие (и тестовые) таблицы для метаалгоритма, полученные при разных разбиениях (см. рис. 2): здесь мы получаем несколько ответов для каждого объекта тестовой выборки — их усредняют. На практике такая схема блендинга сложнее в реализации и более медленная, а по качеству может не превосходить обычного усреднения.

Второй способ борьбы за использование всей обучающей выборки — реализация классического стекинга. Ясно, что совсем не делить обучение на подвыборки (т.е. обучить базовые алгоритмы на всей обучающей выборке и потом для всей выборки построить метапризнаки) нельзя: будет переобучение, поскольку в каждом метапризнаке будет «зашита» информация о значении целевого вектора (чтобы понять, представьте, что один из базовых алгоритмов — ближайший сосед). Поэтому выборку разбивают на части (фолды), затем последовательно перебирая фолды обучают базовые алгоритмы на всех фолдах, кроме одного, а на оставшемся получают ответы базовых алгоритмов и трактуют их как значения соответствующих признаков на этом фолде. Для получения метапризнаков объектов тестовой выборки базовые алгоритмы обучают на всей обучающей выборке и берут их ответы на тестовой.

Здесь тоже желательно реализовывать несколько разных разбиений на фолды и затем усреднить соответствующие метапризнаки (или ответы стекингов!). Но самый главный недостаток (классического) стекинга в том, что метапризнаки на обучении (пусть и полноценном — не урезанном) и на тесте разные. Для объяснения возьмём какой-нибудь базовый алгоритм, например, гребневую регрессию. Мета-признак на обучающей выборке — это не ответы какого-то конкретного регрессора, он состоит из кусочков, которые являются ответами разных регрессий (с разными коэффициентами). А метапризнак на контрольной выборке вообще является ответом совсем другой регрессии, настроенной на всём обучениии. В классическом стекинге могут возникать весьма забавные ситуации, когда какой-то метапризнак содержит мало уникальных значений, но множества этих значений на обучении и тесте не пересекаются!
Часто с указанными недостатками борются обычной регуляризацией. Если в качестве метаалгоритма используется гребневая регрессия, то в ней есть соответствующий параметр. А если что-то более сложное (например бустинг над деревьями), то к метапризнакам добавляют нормальный шум. Коэффициент с которым происходит добавка и будет здесь некоторым аналогом коэффициента регуляризации (это очень интересный приём — поиграйтесь на досуге).
Полезно посмотреть работу моего студента Саши Гущина про его попытки (весьма удачные) создать «стекинг без недостатков».
Качество стекинга
Стоит отметить, что не всегда стекинг существенно повышает качество лучшего из базовых алгоритмов. На рис.4 показаны результаты для простейшей модельной задачи (о ней — ниже). Видно, что качество блендинга и стекинга сравнимы с лучшим базовым алгоритмом. Но если этот алгоритм убрать из базовых, качество стекинга падает не сильно.

А вот (рис.4b) качество на случайно взятой реальной задаче (я взял данные проходящего сейчас соревнования mlbootcamp, несколько случайных лесов и LightGBM-ов в качестве базовых алгоритмов).

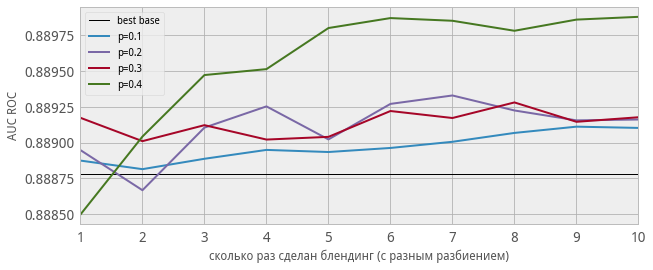
Также отметим, что здесь мы использовали однократный стекинг (без усреднения), усреднение ещё повышает качество, но незначительно (см. рис. 5-5b).

Кстати, для стекинга нужны достаточно большие выборки (скажем, в двумерных модельных задачах он «начинает работать», когда число объектов измеряется десятками тысяч). На малых выборках он тоже может работать, но тут надо аккуратно подбирать базовые алгоритмы и, главное, метаалгоритм.
Природа алгоритмов
В отличие от бустинга и традиционного бэгинга при стекинге можно (и нужно!) использовать алгоритмы разной природы (например, гребневую регрессию вместе со случайным лесом). Для формирования мета-признаков используют, как правило, регрессоры.
Но стоит помнить о том, что правильное применение стекинга — это не взять кучу разных алгоритмов и «состекать». Дело в том, что для разных алгоритмов нужны разные признаковые пространства. Скажем, если есть категориальные признаки с малым (3-4) числом категорий, то алгоритму «случайный лес» их можно подавать «как есть», а вот для регрессионных (ridge, log_reg) нужно предварительно выполнить one-hot-кодировку.
Метапризнаки
Поскольку это ответы уже натренированных алгоритмов, то они сильно коррелируют. Это априорно один из недостатков подхода. Для борьбы с этим часто базовые алгоритмы не сильно оптимизируют. Иногда здорово срабатывают идеи настройки не на целевой признак, а, например, на разницу между каким-то признаком и целевым.
Стекинг на практике
Стекинг можно и нужно использовать при решении реальных бизнес-задач, поскольку при умелом построении композиции алгоритмов он даже помогает бороться с типичными проблемами реальных данных. Например, одна из таких проблем — значения признаков у нас появляются в реальном времени и в будущем могут быть артефакты, которые мы не наблюдали в прошлом. Скажем, из опыта автора: «сломались» счётчики посещений интернет-ресурсов и начали показывать аномальные значения (в 100 раз больше истины). Это совершенно губит регрессионные алгоритмы (у них ответы также могут возрасти в 100 раз), но если регрессии использовать как базовые алгоритмы (натренировать на разных признаковых пространствах), а в качестве метаалгоритма использовать что-то основанное на деревьях, то ответ такого стекинга уже не будет совсем неадекватным даже при «повреждении» некоторых признаков.
Использование признаков вместе с метапризнаками
Автор знает несколько случаев (у своих учеников), когда это повышало качество. Есть также и случаи, когда это приводит лишь к переобучению. В любом случае: при решении практической задачи для бизнеса лучше так не делать! Модели становятся совсем неинтерпретируемыми и «неуправляемыми».

Деформация признаков
Очень полезный приём, о котором часто забывают — преобразование (деформация) метапризнакового пространства. Скажем, вместо стандартных метапризнаков (ответов алгоритмов) можно использовать мономы над ними (например, все попарные произведения).
Параметры стекинга
У самого стекинга (а не только алгоритмов, из которых он состоит) есть параметры. Скажем, число фолдов. Как правило выбирают максимальное, при котором он ещё работает (обучается) за приемлемое время. На рис.7 показано качество в модельной задаче от числа фолдов при разном уровне «регуляризационного шума».

Выбор метаалгоритма
Здесь всё просто — он должен оптимизировать заданный функционал качества. От базовых алгоритмов это, вообще говоря, не требуется. Вообще-то, от того, какую композицию Вы будете использовать в ансамбле, сильно зависит качество. Например, в задаче бинарной классификации с функцией ошибки log_loss, если у Вас есть несколько хороших алгоритмов, то сложно придумать стекинг, который их улучшит… Если в качестве метаалгоритма взять гребневую регрессию, то она совсем не годится для log_loss-a, а если логистическую, то обратите внимание на вид Вашего алгоритма: Вы в аргумент сигмоиды «вставляете» линейную комбинацию «почти правильных ответов», вряд ли Вы получите что-то более близкое к правильному ответу…
Связь с другими техниками
Удивительно, но стекинг является обощением практически всего, с чем приходится иметь дело при решении задач. Например, рассмотрим классическую проблему — кодирование категориальных признаков. Если мы для кодирования используем значение целевого вектора, то это эквивалентно тому, что мы получаем метапризнак с помощью байесовского алгоритма, который использует лишь один (кодируемый категориальный) признак. Если мы так закодируем все категориальные признгаки, а потом обучим какой-нибудь алгоритм, то получается, что мы неявно применили стекинг. Ну, а изображение схемы применения стекинга часто похоже на изображение нейронной сети, просто вместо стандартных нейронов используются названия алгоритмов.

Многоуровневый стекинг
Естественное обобщение стекинга — сделать его многоуровневым, т.е. ввести понятие мета-мета-признака (и мета-мета-алгоритма) и т.д. Опять же, лучше воздержаться от этого при решении реальных бизнес-задач, а в спортивном анализе данных так часто делают.
История
Стекинг был предложен Д. Волпертом в 1992 году, хотя, как я уже писал, он постоянно переоткрывается, и, возможно, кто-нибудь использовал уже подобную технику под другим названием раньше. Кстати, Д. Волперт больше известен как автор серии теорем «No free lunch».
Термин «блендинг» вроде бы ввели в обиход победители конкурса Netflix. Есть постоянная путаница, что называть «стекингом», а что «блендингом». Часто негласно считают, что простые схемы стекинга лучше называть «блендингом».
Удивительно, но стекингу посвящено очень мало научных статей, хотя он порождает очень много теоретических вопросов. Например, как решать задачи машинного обучения в пространстве метапризнаков? Ясно, что в отличие от традиционного признакового пространства здесь все признаки сильно коррелируют друг с другом и с целевым признаком. Это, например, может предъявлять особые требования к регуляризации.
Стекинг часто используют в спортивном анализе данных, в частности, автор с его помощью побеждал в соревнованиии Kaggle WISE 2014 и занимал 3е место в TunedIt JRS 2012.
Геометрия стекинга
Просто приведу пример модельной задачи: линии уровней базовых регрессоров, блендинга и стекинга.

Код
В интернете можно найти разные реализации стекинга, например brew и heamy. Если Вы плотно занимаетесь машинным обучением, то лучше сделать свою. В какой-то момент Вы захотите что-нибудь модифицировать и тогда она Вам пригодится.
Вот ноутбук, в котором есть (достаточно простая) авторская реализация.

Если говорить обо мне, человеке, очень поверхностно знакомым с машинным обучением, то объяснение слишком сложное. Я не хочу критиковать — тема интересная. Но что бы мы не делали — это всегда можно сделать лучше. В данном случае для меня лучше — понятнее.
Если показать этот текст многим людям, то большинству он будет не понятен. Идея в том, что можно придумать, как объяснять проще. Как же можно объяснять проще?
Давайте подумаем. Например, вот мы хотим рассказывать о стекинге и блендинге. Давайте я объясню данную идею на реальной задаче. Например, есть на Каггле задача «Титаник».
Далее делаем так: я пишу текст, объясняющий блендинг и стекинг, а затем показываю, как это применять и как это работает в реальном примере.
Как могла бы выглядеть более понятная статья:
1. Меньше непонятных терминов. Для автора они очевидны. А для далёкого читателя — он их не знает. Стараться использовать как можно меньше спецефических терминов. Автор думает, что многие термины для читателя очевидны, но он забывает, что читатели-то разные. Есть его студенты — может быть, им это всё понятно. А есть совсем другие люди — для них лучше минимум жаргона, потому что они всё равно его не знают.
2. Теория — десять строк
3. Практика — используем это на реальной задаче «Титаник», 10 строк.
4. смотри пункт 2.
Иными словами, в статье много теории. А теория лучше понимается на практике. А практики здесь нет, а поэтому текст становится ещё сложнее понимать людям, очень далёким от этой области.
Вывод: тема интересная, но объяснено для людей, далёких от данной области, очень сложно. Нужно упрощать. Чем проще будет текст, тем большее количество людей сможет в нём разобраться. Я пишу этот текст не для того, чтобы покритиковать, а в надежде, что автор напишет следующий пост понятнее, и я в нём смогу разобраться.
Пример: «Если в качестве метаалгоритма взять гребневую регрессию, то она совсем не годится для log_loss-a, а если логистическую, то обратите внимание на вид Вашего алгоритма»
Я не знаю, что такое маталгоритм. Я не знаю, что такое гребневая герессия. Я не знаю, что такое log_loss. Одно предложение — три непонятные слова. Но я уверен, что идею статьи можно объяснить без всяких этих сложных слов. Например, есть курс машинного обучения на coursera — китаец какой-то там преподаёт. Там всё очень понятно. Там нет заумных слов. Ты слушаешь его курс, и ты всё понимаешь, хотя язык не русский. Я здесь ты читаешь на русском и ничего не понимаешь.
Предложение — писать все статьи проще. Тогда, может быть, я тоже начну их понимать, как прекрасно понял обучающий курс на coursra преподавателя из Стэндфорда.
Здравствуйте, Роман. Спасибо за отзыв. Это всегда здорово, когда есть обратная связь между автором блога и читателями.
Вы полностью правы — текст не будет понятен человеку «поверхностно знакомому с машинным обучением». Более того, возможно, он не будет понятен и человеку, который прошёл несколько вводных курсов по ML.
Меня просили по мере возможности выкладывать материалы моего курса ПЗАД, который я читаю магистрам МГУ. Вот пример такого материала — он рассчитан на тех, кто уже сдал годовой курс Воронцова по ML. Адаптировать его для произвольного читателя нет смысла: стекинг изучают только после того, как узнали все модели алгоритмов и поработали с ними.
Правда, мне показалось, что Вы не особо попытались разобраться с текстом, не увидев подходящей для Вас формы изложения. Вот Вы пишете, что в предложении «Если в качестве метаалгоритма» Вы не знаете,
1) что такое метаалгоритм. Но это объясняется ещё в первом абзаце: алгоритм, с помощью которого делают ансамблирование. А во втором абзаце объясняется, как это делается. Странно, что в 18м абзаце этот термин вызвал вопрос…
2) что такое гребневая регрессия. Согласен, я нигде не пишу о том, что это. Но этот термин специалист по ML знать обязан. Учиться стекингу не узнав стандартные регрессионные алгоритмы бессмысленно! Многие тонкости, о которых я здесь говорю, невозможно понять не поработав плотно с регрессией. А я хочу рассказать именно о тонкостях, а не объяснить, что такое «стекинг».
3) что такое log_loss. При первом употреблении этого термина (в этом же абзаце, откуда Вы взяли предложение) я сделал гиперссылку. Формат интернет-публикаций как раз подразумевает, что дополнительную информацию узнают «кликая на незнакомые термины». Опять же, странно, что Вы не знаете, что это такое, дойдя до обсуждаемого предложения.
Практика тоже есть в нужном (для моей целевой аудитории) объёме, поскольку я дал ссылку на код, с реализацией стекинга… конечно, для этого нужно понимать Python. И опять же, возможно, это не для новичка.
Подытожу, да, этот текст не для новичка, но все нужные термины я всё-таки по тексту пояснил, а базовые термины читатель знать должен, если хочет узнать про стекинг (в том контексте, в котором я его описал). Этот блог больше для полу-профессионалов (точнее так: людей, которые активно занимаются анализом данных) — я рассказываю о каком-то своём опыте — они мне могут возразить или подтвердить что-то (в этом и есть моя мотивация вести блог).
П.С. Вы имели в виду, конечно, курс Эндрю Ына https://ru.coursera.org/learn/machine-learning Прекрасный курс!
П.П.С. Хотелось бы, конечно, услышать мнение о заметке от людей из моей целевой аудитории… уверен, она не очень удачная (Роман во многом прав), но хотелось бы критику чуть в другой плоскости.
Роман,
если Вы прошли курс Эндрю Ына, тогда вообще не понятно, почему у Вас такие вопросы.
Если не прошли – пройдите до конца. Еще материал хорошо подают в специализации Яндекса и МФТИ на Coursera. Также мы, сообщество OpenDataScience, сейчас пишем серию статей на Хабре про основы машинного обучения и анализа данных.
Александр Геннадьевич,
спасибо! Очень не хватало статьи именно на эту тему.
На мой взгляд, статью украсил бы жизненный пример, в котором стекинг хорошо работает. Хоть я и понимаю, что это можно найти в описаниях решений Kaggle-контестов, но, возможно, стоит привести пример, чтоб статья была самодостаточной. Или дать ссылку, если решение уже описано (Вы даете ссылки на Springer с описанием решений WISE 2014 и TunedIt JRS 2012, но вдруг эти описания есть на русском).
Еще интересно было бы порассуждать о применении стекинга в боевых системах. Многие говорят, что прод и стекинг – вещи несовместимые. Но я знаю некоторые примеры. В Goldman Sachs есть большой алгоритм, прогнозирующий цены на кучу деривативов (опционов, фьючерсов и т..д) на американском рынке. В качестве входных признаков он использует множество (несколько сотен) прогнозов других моделей (обычно простых, линейных). То есть это один большой стекинг.
PS. не рекламы ради, но как-то я переводил на русский обзор методов построения ансамблей в задаче классификации. https://www.researchgate.net/publication/278019662_Istoria_razvitia_ansamblevyh_metodov_klassifikacii_v_masinnom_obucenii
Здравствуйте, Юра! Спасибо, я встречал Ваш обзор — очень хороший, я его порекламирую, когда буду писать обзорный пост про ансамбли;) была у меня такая задумка.
По поводу жизненного примера…. честно говоря, для меня самого пока большая загадка, а работает ли он. В том смысле, что есть ли задачи, в которых высокое качество можно получить исключительно стекингом? Победы на кэгле пока меня в этом не особо убеждают по разным причинам. Например, я верю, что генерация хороших признаков под конкретные модели должна быть «сильнее» стекинга. Но это просто вера…
Про прод и стекинг: я написал, что можно и нужно использовать, только с умом. Я сам иногда делал, но там был совсем простой блендинг и смешивались 2-3 модели. Так чтобы где-то в проде было куча алгоритмов и они стекались, такого у меня честно не было. Я тоже слышал про их использование в финанасах, но не знаю деталей. Часто там некоторый эвристический ансамбль, который при желании можно назвать стекингом.
Тут Стас мог бы рассказать, как кванты стекингом занимаются. Но вряд ли захочет 🙂
В обзоре можно много ссылаться на Кунчеву, она из тех немногих, кто пытается теоретически обосновать композиции алгоритмов. Еще у Констанина Владимировича Рудакова целая теория про алгебру над ответами моделей, но честно говоря, не знаю, насколько она современна, и может ли она быть сейчас кому-то полезна. Хотя меня не покидает ощущение, что большинство современных подходов к композициям алгоритмов действительно были известны в еще советским ученым (и можно даже преуспеть на Kaggle, если обратиться к нужным источникам). Людмила Кунцева ссылается как-то на брошюрку за 90 копеек (!), в которой многие из таких подходов описаны.
Было бы интересно в обзоре увидеть и Ваш взгляд на этот вопрос.
Я про Стаса тоже подумал:) нее, пусть молчит. Это ноу-хау.
А это больная тема… У меня же самого докторская диссертация про «алгебру над ответами моделей». Но я стараюсь про это не рассказывать:)
Да, сорри, добрый день! 🙂
Еще интересно, насколько вообще теория преуспела в обосновании методов, хорошо работающих на Kaggle. Например, известно, что хорошо объединяются в ансамбли «непохожие» алгоритмы, скажем, линейные, метрические и основанные на деревьях. Но как определяется формально «непохожесть»?… Я встречал только у Кунчевой семейство эвристик типа diversity. Может быть, Вы знаете примеры, когда чтение литературы помогало в соревнованиях Kaggle, и так ли вообще все сейчас печально с теоретическим обоснованием стекинга и блендинга?
алала)) ололо))) никому нечего не расскажу
PS. это Юра Кашницкий, просто демонстрирую косяк wordpress.
Возможно, навязчивое предложение, но не хотели бы на Хабре писать статьи с OpenDataScience? https://habrahabr.ru/company/ods Сейчас у нас там пойдут и статьи на продвинутые темы, не только курс для начинающих.
Почему косяк? Я тут, как админ, ip-адреса могу смотреть.
Не знаю, ответственность большая. Здесь мой блог — мои правила. А там от имени сообщества…
Ну пока с ответственностью справляемся, а Вам есть что и на Хабре рассказать. Там система инвайтов (они зарабатываются за хорошие посты) – для Вас найдем инвайт 🙂
Да, я знаю про систему инвайтов.
А какой смысл публиковаться на Хабре? Я понимаю, что там огромная аудитория и автор становится популярным… Но если нет цели «себя продать» или «стать известным среди Хабр-тусовки», то зачем? Или я что-то не понимаю?
Да вообще в тех же целях, в каких и персональные блоги ведут. Я своим слушателям даю ссылку на свой аккаунт на Хабре, особенно это актуально теперь, когда мы начинаем там статьи по машинному обучению писать. Иногда они вопросы уточняющие задают.
Просто что хорошо на Хабре – это саморегулирование. И да, приятно быть частью этого сообщества, я много всего полезного узнал на Хабре – регулярно его читаю. В какой-то момент решил тоже быть полезным Хабр-сообществу.
Не думаю, что кто-то ставит себе задачу с помощью Хабра продаться. Вот то что через Хабр начинают продавать – это да, проблема, корпоративные блоги в целом понизили качество контента.
Здравствуйте, Александр!
> В том смысле, что есть ли задачи, в которых высокое качество можно получить исключительно стекингом?
А что Вы скажете про AlphaGo? Фактически, они применили стекинг к уже обученным разным по природе нейросетям, хотя в статье они используют более общий термин «ансамбль». Результаты, очевидно, супер. Первая модель, если не изменяет, давала всего лишь 54% предсказания хода Го-профи, остальные примерно на том же уровне. И ни одна из базовых (известных нам) моделей даже близко не подошла к тому же уровню качества.
«Роман,
если Вы прошли курс Эндрю Ына, тогда вообще не понятно, почему у Вас такие вопросы.
Если не прошли – пройдите до конца».
Я прошёл 8 недель из 11 — сдал все задания на хорошие оценки. Но эту статью я начал читать — но мне непонятно. Я понял приблизительно суть: что мы используем много разных алгоритмов, а потом как-то их смешиваем, чтобы получить более точные данные, но всё равно понял это я очень смутно.
Я попробую её внимательнее прочитать, а потом попробую объяснить так, как следует объяснять для людей из «нецелевой аудитории этого блога». Попробую переделать эту статью в понятную для нецелевой аудитории этого блога (то есть для таких как я) — выложу её на Хабре. Но только если позднее я её ещё раз перечитаю и смогу её понять.
«Правда, мне показалось, что Вы не особо попытались разобраться с текстом, не увидев подходящей для Вас формы изложения. Вот Вы пишете, что в предложении «Если в качестве метаалгоритма» Вы не знаете»
Я начал читатью эту статью как обычный текст, не особо вчитываясь. Просто начал читать как, например, статью о футболе. Когда же я читаю материалы о спорте, я просто пробегаю глазами по тексту. Вот также я начал читать Вашу статью — да, непонятно. Честно об этом написал.
Но мне будет интересно попробовать в ней разобраться позднее внимательнее и затем попробовать изложить её по-другому (посмотреть, что из этого у меня получится)
«Просто начал читать как, например, статью о футболе.»
Вам самому не смешно? Не беспокойте тогда окружающих своим непониманием.
И перед тем как писать на Хабр, тоже разберитесь в теме. Хотя мое личное мнение – не стоит, оставьте это тем, у кого есть необходимый опыт.
Ну почему? Такой подход имеет право на жизнь. Образование должно приносить удовольствие… и действительно, узнавание новых вещей должно быть в форме интересного рассказа.
Другое дело, что я абсолютно уверен, что то, что хотел рассказать я, не получится передать «как интересную историю». И это не образовательная заметка. И образование бывает разных уровней. Чем выше, тем сложней сделать интересней и всё сложнее обойтись без терминологии.
Короче, я хочу провести эксперимент: получится у меня понять и объяснить в развлекательной манере — хорошо, не получится — ничего страшного. Пытка не пытка.
Теперь моя задача — очень внимательно прочитать данную статью, а потом задать здесь вопросы (что непонятно).
А затем, если я смогу это понять, — попробовать объяснить в развлекательной манере.
Так что, уважаемый Александр Дьяков, ждите от меня вопросы в этой теме. Они обязательно будут, но после очень внимательное прочтения вашей статьи.
И после очень внимательного прочтения имени Александра Геннадьевича.
Уважаемый Александр Геннадьевич, я начал очень внимательно читать Вашу статью, хотел бы в ней разобраться, но некоторые моменты мне не понятны. Начнём с первого вопроса. Буду признателен, если Вы сумеете мне их объяснить. Заранее спасибо. Вопросы только по первым двум абзацам (дальше пока смысла идти нет — какой смысл читать дальше, если ты не понимаешь начала?)
«Простейшая схема стекинга — блендинг (Blending): обучающую выборку делят на две части. На первой обучают базовые алгоритмы. Затем получают их ответы на второй части и на тестовой выборке. Понятно, что ответ каждого алгоритма можно рассматривать как новый признак (т.н. «метапризнак»). На метапризнаках второй части обучения настраивают метаалгоритм. Затем запускают его на метапризнаках теста и получают ответ».
Мне не совсем это понятно. Чтобы лучше разобраться в тексте, давайте поговорим о «Титанике» — всегда лучше видеть конкретный пример перед глазами. Все знают самое популярное соревнование на Каггле, «Титаник». Там есть пассажиры. Наша цель — предсказать, кто из них утонул, а кто выжил. Давайте, разбираясь в вашей статье держать перед глазами этот пример и только его.
«Простейшая схема стекинга — блендинг (Blending): обучающую выборку делят на две части. На первой обучают базовые алгоритмы. Затем получают их ответы на второй части и на тестовой выборке».
Наверное, здесь имеется в виду, что нашу базу Титаника нужно разделить на две части. В Кагле даётся 800 записей тренировочной выборки и примерно столько же записей тестовой выборки. Имеется в виду, наверное, что нам нужно разделить тренировочную базу на две части (под тренировочной базой понимается в виду база, где даны все данные пассажира (фамилия, цена на билет, возраст и т.д.), в том числе, он умер или он жив; под тестовой выборкой понимаются все данные пассажиры, но без информации, выжил пассажир или умер).
Итак, мы делим базу Титаника на две части: у нас в тренировочной базе было 800 записей. Теперь у нас будет 400 записей (первая часть, где мы тренируем алгоритмы) плюс 400 записей.
Мы натренировали наши алгоритмы на первой части, теперь мы хотим понять, какие ответы дадут наши алгоритмы на второй части. Например, первый алгоритм говорит: «Василий Васильевич умрёт». Теперь мы хотим узнать, а что скажет наш агоритм о Степане Степановиче (умер он или нет).
Если я понял это неправильно, поправьте, пожалуйста.
«Понятно, что ответ каждого алгоритма можно рассматривать как новый признак (т.н. «метапризнак»). На метапризнаках второй части обучения настраивают метаалгоритм. Затем запускают его на метапризнаках теста и получают ответ».
Допустим, что наш алгоритм предсказал, что Степан Степанович умер — он дал нам такой ответ. Тогда этот ответ должен стать признаком.
Давайте упростим ситуацию: у нас есть Стёпа, Петя, Вася, Маша, Катя (вторая часть тренировочной базы)
Наш алгоритм, натренированный на первой части, говорит, допустим, что Стёпа умер, Петя выжил, Вася умер, Маша умерла, Катя выжила (ещё раз объясню, наш алгорит тренировался на первой части тренировочной базы, на других людях, а сейчас мы тренируем алгорит на новых людей, из второй части тренировочной базы).
Мы получаем табличку в результате действия нашего алгоритма: фамилия — выжил или умер. Если выжил, то 1. Если умер, то 0.
Теперь эти 1 или 0 стали новыми признаками.
«На метапризнаках второй части обучения настраивают метаалгоритм. Затем запускают его на метапризнаках теста и получают ответ».
Здесь мне не совсем понятно. Вот мы получили табличку алгоритма, натренированного на первой части, на второй части:
Стёпа — 0 (цифра 0 или 1 — это метапризнак)
Петя — 1 (выжил)
Вася — 0 (умер)
Маша — 0 (умер)
Катя — 1 (выжил)
Что значит словосочетание «настраиваем метаалгоритм»? Непонятно, что понимается под словосочетанием «настраивать»? Что это такое? Что понимается под такими действиями?
Дальше непонятно следующее «Затем запускают его на метапризнаках теста и получают ответ». Честно говоря, я не понимаю, что это значит на Титанике. У нас алгоритм, натренированный на первой части. С его помощью мы получили табличку Стёпа — 0, Петя — 1, Вася — 0 и так далее.
Не совсем понятно следующее, что означает «Затем запускают его на метапризнаках теста и получают ответ». То есть, что имеется в виду, что у нас есть табличка: мы что, используя эти цифры 0 или 1, хотим предсказать реальные значения, выжил ли Стёпа или умер, выжил ли Петя или умер, выжил ли Вася или умер? Так нужно понимать Ваш текст или нет?
До слов «Теперь эти 1 или 0 стали новыми признаками. » Вы всё правильно поняли.
Теперь учтите, что всё, что Вы описали — Вы проделываете с несколькими алгоритмами, а значит получаете несколько мета-признаков. т.е. у Вас табличка: по строкам «Стёпа», «Петя» и т.д., по столбцам — ответы «умер ли» по версии первого алгоритма, второго и т.д.
Стёпа — 01010
Петя — 01000
Вася — 11111
Маша — 11000
Катя — 00000
Теперь считаем, что эта таблица и будет обучающей для нашего нового алгоритма, который мы назвали «метаалгоритм». Настраивать = обучать (fit = train).
По поводу «метапризнаков теста»… алгоритмы, которые получили ответы для Стёпы, Пети и т.д. (из второй части обучения) мы может запустить и на тестовой таблице, скажем там
Даша — 11000
Костя — 01110
Маша -00001
И эту табличку считать тестовой для нашего метаалгоритма.
Там есть картинка, на ней всё показано (рис.1).
П.С. Я правильно понимаю, что у Вас «не математическое» образование?
Роман, спасибо за Вашу нацеленность на детали! Думаю разбор комментариев действительно помог понять многим, что тут происходит в статье. Два дня к этой ссылке присматриваюсь, уже хотел в утиль отправить, хорошо комменты начал читать.
Статья сложная для восприятия, особенно схемы
«Я правильно понимаю, что у Вас «не математическое» образование?»
Я вообще-то закончил мат-мех СПбГУ, но я туда поступал чисто ради программирования, поэтому честно сдавал лишь то, что связано с программированием, а остальное сдавал с помощью метода «списывания».
А там можно учиться «чисто программированию»?
Скажем, на ВМК МГУ есть математические потоки и программистский, На последний идут, вроде как, чтобы программировать, но распределение по потокам идёт после 2 курса. Поэтому 2 года все студенты варятся «в одном котле» и проходят базовые дисциплины (матан, линейка, тервер, дискру и т.д.), т.е. у нас не получится сразу заниматься «чистым программированием» (впрочем, как и чистой математикой).
Я думаю, что образование будущего должно стать иным. То есть ты приходишь в Университет. Тебе не должны заставлять учиться. Ты должен сам выбирать интересные для себя предметы. Думаю, что через 100 лет не останется привычных нам Университетов, а будет лишь coursera: каждый студент будет выбирать любые предметы первые три года обучения. Затем его предпочтения будет анализироваться: то, что тебе интересно делать — продолжай это делать. С третьего по пятый курс — половина предметов по выбору, а половина — какие предметы нужны.
Я думаю, что через сто лет школа тоже изменится.
1. Меньше будет принудительных преметов. Больше будет выбора.
2. Не будет учителя в классе. Учить будут лучшие педагоги мира через coursera.org или её аналоги через интернет (может быть, учить будут роботы)
3. Оценки и предпочтения детей будут анализироваться. И то, что человек больше любит или то, что у человека лучше получается — это будет даваться в углублённом объёме. То, что человеку не нравится — в уменьшенном.
Я бы хотел на первом курсе много программирования, а у меня было очень много математики. Я не хотел изучать химию в школе. Но я бы хотел намного больше биологии, у меня были превосходные оценки по истории — я бы хотел больше истории. Но меня никто никогда не спрашивал, всё давали всем одинаков, хотя у всех были разные склонности. Задача образования будущего — уйти от обязательных предметов к тому, что интересно людям (конечно, какой-то минимум должен оставаться). Уверен, что образование будет очень быстро меняться: здесь будет такая же революция, как и в транспорте.
И ещё один большой недостаток современной системы образования: все понимают с разной скоростью. Стоит лектор перед аудиторией. Но один будет его понимать, а второму нужно больше времени разобраться.
Если образование будет в виде глобальной coursera — то ты смотришь и можешь послушать лекцию ещё один раз. Или замедлить какой-то момент. Или послушать его десять раз.
Если все будут сидеть перед мониторами и слушать с той скоростью, с какой люди хотят — то скорость обучения резко повысится. А роль преподаватели — не читать лекцию, а просто объяснять то, что студент не понял.
Школа сегодня — сидят школьники, у всех одна и та же программа, хотя каждый отличается друг от друга, и каждому материал нужно давать немного иначе.
Школа будущего — сидит школьник, и каждый видит на мониторе разных преподавателей, разные курсы, с разной сложностью. А если он что-то не понял, то через монитор спрашивает у какого-то учителя на форуме или через Скайп, или вживую.
От идеи «всем всё одинако» к идее «всем всё по-разному».
«А там можно учиться «чисто программированию»?»
Понятно, что я немного знаю математику. Я брал интегралы, решал диф. уравнения, учил мат-ман и так далее. Но я учил математику по типу «лишь бы сдать» — поэтому не очень в ней хорош.
За семь дней до экзамена ксерил конспект и начинал зубрить основные идея курса. Чтобы получить тройку, нужно запомнить все главные теоремы, запомнить некоторые базовые вещи (можно сделать за 7 дней), получить зачёт, иметь друзей в группе (взаимопомощь). Иметь тройку по математике на мат-мехе СПбГУ не так сложно. Вот иметь пять по математике на мат-мехе — это намного сложнее.
Я бы хотел убедиться, что понял второй абзац правильный: самый простой способ разобраться — взять самый элементарный пример.
«Простейшая схема стекинга — блендинг (Blending): обучающую выборку делят на две части. На первой обучают базовые алгоритмы. Затем получают их ответы на второй части и на тестовой выборке. Понятно, что ответ каждого алгоритма можно рассматривать как новый признак (т.н. «метапризнак»). На метапризнаках второй части обучения настраивают метаалгоритм. Затем запускают его на метапризнаках теста и получают ответ».
Пусть у нас есть Маша, Вася, Катя, Петя — тренировочная выборка (знаем, они погибли они или нет)
Александр, Боря, Зина, Даша — тестовая выборка (не знаем, погибли они или нет)
Мы делим тренировочную выборку на две части: Маша, Вася (первая часть) и Катя, Петя (вторая часть).
Затем мы берём некое количество алгоритмов, например, три: A1 — логистическая регрессия, A2 — метод ближайших соседей, A3 — случайный лес.
Теперь тренируем эти алгоритмы на первой части тренировочной выборки (Маша, Вася). Когда мы их натренируем, то запускаем их для второй части тестовой выборки и получаем:
Катя 0 1 1 (метапризнак, три цифры, потому что три алгоритма, 0 — предсказание алгоритма A1, 1 — предсказание алгоритма A2 и т.д.)
Петя 0 0 0
Теперь мы берём некий алгоритм, например, логистическую регрессию, скажем, B1. И тренируем алгоритм B1 (метаалгоритм). По этим трём цифрам мы хотим предсказать, люди погибли или нет.
Когда мы натренируем алгоритм B1 (метаалгоритм), то теперь мы готовы приступать к решающей стадии: к тестовой выборки. Запускаем для тестовой выборки натренированный алгоритмы A1, A2, A3. Получаем значания для каждого человека в тестовой выборке (три числа), а затем запускаем для этих чисел натренированный алгоритм B1 (то есть переводим эти три числа в результат: выжил человек или нет).
Правильным ли образом я понял Ваш абзац теперь?
Да, верно.
Хотел бы разобраться в этом абзаце.
«Самый большой недостаток блендинга (в описанной реализации) — деление обучающей выборки. Получается, что ни базовые алгоритмы, ни метаалгоритм не используют всего объёма обучения (каждый — только свой кусочек). Понятно, что для повышения качества надо усреднить несколько блендингов с разными разбиениями обучения. Вместо усреднения иногда конкатенируют обучающие (и тестовые) таблицы для метаалгоритма, полученные при разных разбиениях (см. рис. 2): здесь мы получаем несколько ответов для каждого объекта тестовой выборки — их усредняют. На практике такая схема блендинга сложнее в реализации и более медленная, а по качеству может не превосходить обычного усреднения».
Здесь мне не совсем понятен следующий момент: как конкретно мы будем усреднять значения. Опять же давайте вернёмся к «Титанику»: я хочу на сто процентов понимать всё верно.
Пусть у нас есть Маша, Вася, Катя, Петя — тренировочная выборка (знаем, они погибли они или нет)
Александр, Боря, Зина, Даша — тестовая выборка (не знаем, погибли они или нет)
Мы делим тренировочную выборку на две части: Маша, Вася (первая часть) и Катя, Петя (вторая часть).
Затем мы берём некое количество алгоритмов, например, три: A1 — логистическая регрессия, A2 — метод ближайших соседей, A3 — случайный лес.
Теперь тренируем эти алгоритмы на первой части тренировочной выборки (Маша, Вася). Когда мы их натренируем, то запускаем их для второй части тестовой выборки и получаем заветную таблицу (назовём её T1):
Катя 0 1 1 (метапризнак, три цифры, потому что три алгоритма, 0 — предсказание алгоритма A1, 1 — предсказание алгоритма A2 и т.д.)
Петя 0 0 0
Теперь разделим людей по-другому, нашу тренировочную выборку: Маша, Вася, Катя (первая часть тренировочной выборки), Петя (вторая часть тренировочной выборки).
Далее делаем то же самое и получаем таблицу T2.
Петя 0 1 1 (здесь только один Петя, потому что он один во второй части тренировочной выборки)
Теперь что, мы должны усреднить таблицы T1 и T2? Таблица T1 — в ней 4 человека (у каждого три цифры), таблица T2 — в ней 4 человека (у каждого три цифры).
Мы просто усредняем эти таблицы и начинаем тренировать метаалгоритм B1 по нашей усреднённой таблице ((T1+T2)/2)?
1. Правильно ли я это понял? Если я понял это правильно, то как мы будем учить метаалогоритм B1: в первом случае Катя и Петя будут использоваться для обучения алгоритма B1, во втором случае — только Петя. Или мы должны научить метаалгоритм B1 на Кате и Пете для блендинга 1 и затем метаалогоритм B1 только на Пете для блендинга 2, и затем усреднить ответы двух метаалгоритмов, в этом что ли идея усреднения?
2. Если я понял это правильно, то есть вопрос: алгоритмы для блендинга 1 и алгоритмы для блендинга 2 — они должны быть одинаковыми? Скажем, для блендинга 1 мы используем три алгортима A1, A2, A3 (логистическая регрессия, случайный лес, метод ближайших соседей). Можем ли мы использовать для блендинга 2 другое количество алгоритмов: A1, A2, A3, A4 — или там и там их число должны быть одинаковым? Если можем, то как мы будем их усреднять? Наверное, мы в таблице (T1+T2)/2 берём значение для A4, равное A4, верно?
Тут Вы поняли неверно.
У меня написано «усреднить несколько блендингов с разными разбиениями обучения».
Что такое блендинг? Это функция, которая является композицией матаалгоритма M и базовых алгоритмов A1, A2, A3 (пусть их 3):
M(A1, A2, A3): объект -> ответ
Когда произносят фразу «усреднить чего-то» и это что-то является функцией (а любой «алгоритм» машинного обучения это функция, которая описания объектов переводит в метки), то сразу ясно, как усреднять:
усредняют ответы на тестовой выборке.
Здесь правда, есть небольшая некорректность, которая, впрочем, понимается теми, кто занимается ML. Как я писал в первом абзаце, в задачах регрессии — усредняют, в задачах классификации — голосуют. Но в данном примере (Титаник) — бинарная классификация, поэтому также можно усреднить ответы нескольких блендингов и при окончательной классификации сравнивать с порогом 0.5. А вообще, в бинарной классификации часто просят ответ в виде вероятности принадлежности к классу 1, так что и сравнивать с порогом не нужно.
У меня есть ещё один вопрос по следующему параграфу:
«Второй способ борьбы за использование всей обучающей выборки — реализация классического стекинга. Ясно, что совсем не делить обучение на подвыборки (т.е. обучить базовые алгоритмы на всей обучающей выборке и потом для всей выборки построить метапризнаки) нельзя: будет переобучение, поскольку в каждом метапризнаке будет «зашита» информация о значении целевого вектора (чтобы понять, представьте, что один из базовых алгоритмов — ближайший сосед). Поэтому выборку разбивают на части (фолды), затем последовательно перебирая фолды обучают базовые алгоритмы на всех фолдах, кроме одного, а на оставшемся получают ответы базовых алгоритмов и трактуют их как значения соответствующих признаков на этом фолде. Для получения метапризнаков объектов тестовой выборки базовые алгоритмы обучают на всей обучающей выборке и берут их ответы на тестовой.»
Когда мы говорим о тексте, то лучший способ — написать код самому на самом простом примере, потому что слова всегда можно трактовать так, или иначе, а код — это всегда код. Он однозначен.
Для лучшего понимания фолдов, я написал простенький код. Правильно ли я это сделал?
#Эта база Титаника: со всей информаций о пассажирах
test_X = full_X[891:]
#мы разбиваем её на фолды, то есть X1 — первые 148 #значений нашей базы, то есть это первый фолд
train_X1 = full_X[0:148]
#второй фолд и так далее
train_X2 = full_X[148:296]
train_X3 = full_X[296:444]
train_X4 = full_X[444:592]
train_X5 = full_X[592:740]
train_X6 = full_X[740:891]
#train_Y1 — это точные значения о пассажирах в первом #фолде: выжил он или нет.
train_Y1 = train_valid_y[0:148]
#точные значения о пассажирах во втором фолде (пассажир с #номером от 0 до 148)
train_Y2 = train_valid_y[148:296]
train_Y3 = train_valid_y[296:444]
train_Y4 = train_valid_y[444:592]
train_Y5 = train_valid_y[592:740]
train_Y6 = train_valid_y[740:891]
#Теперь мы используем несколько разных алгоритмов
model1 = LogisticRegression()
model2 = RandomForestClassifier(n_estimators=100)
model3 = KNeighborsClassifier(n_neighbors=3)
model4 = SVC()
model5 = GradientBoostingClassifier()
model6 = LogisticRegression()
#тренируем фолды
model1.fit(train_X1, train_Y1)
model2.fit(train_X2, train_Y2)
model3.fit(train_X3, train_Y3)
model4.fit(train_X4, train_Y4)
model5.fit(train_X5, train_Y5)
#предсказываем значения для последнего фолда, то есть
#получаем мета-признак
Y_pred1 = model1.predict(train_X6)
Y_pred2 = model2.predict(train_X6)
Y_pred3 = model3.predict(train_X6)
Y_pred4 = model4.predict(train_X6)
Y_pred5 = model5.predict(train_X6)
#объединяем мета-признаки вместе
train_X6 = pd.DataFrame()
train_X6[«model1»] = Y_pred1
train_X6[«model2»] = Y_pred2
train_X6[«model3»] = Y_pred3
train_X6[«model4»] = Y_pred4
train_X6[«model5»] = Y_pred5
#тренируем модель на последнем фолде
model6.fit(train_X6,train_Y6 )
#получаем наше предсказание
Y_pred = model6.predict(train_X6)
#получем оценку
print(model6.score(train_X6, train_Y6))
Я правильно сделал код?
Нет.
Код для блендинга, кстати, есть в ноутбуке, на который я ссылаюсь в этой статье.
«…обучают базовые алгоритмы на всех фолдах, кроме одного, а на оставшемся получают ответы базовых алгоритмов»
имеется в виду, что каждый алгоритм обучается на объектах, которые входят во все фолды, кроме выделенного.
Посмотрите на рис.3!!!
Спасибо за ссылку на мою библиотеку (heamy), универсальной и гибкой у меня не получилось её сделать. Поэтому, да, очень полезно иметь свою реализацию.
Пожалуйста! Была бы хорошая библиотека, а ссылки на неё появятся;)
Подведем промежуточный итог великого «эксперимента».
(по состоянию на конец вчерашнего дня, когда А.Г., видимо, «наелся»)
Исходная статья: 1537 слов / 11.5K знаков.
Комментарии А.Г.: 928 слов / 6.1K знаков.
Комментарии Р.: 2653 слов / 17.3K знаков.
По-моему, логично, что «эксперимент» завершен в одностороннем порядке.
Если говорить о коде, то вот эта штука у меня не запускается: https://github.com/viisar/brew возникает ошибка ImportError: cannot import name ‘plot_decision_regions’
Но если вместо этой строчки:
from mlxtend.evaluate import plot_decision_regions
Написать:
from mlxtend.plotting import plot_decision_regions
То у меня начинает работать.
Если говорить обо мне, то я реализовал пока самый простой вариант:
«Простейшая схема стекинга — блендинг (Blending): обучающую выборку делят на две части. На первой обучают базовые алгоритмы. Затем получают их ответы на второй части и на тестовой выборке. Понятно, что ответ каждого алгоритма можно рассматривать как новый признак (т.н. «метапризнак»). На метапризнаках второй части обучения настраивают метаалгоритм. Затем запускают его на метапризнаках теста и получают ответ».
На «Титанике», если я не ошибся в реализации кода, то у меня получилось следующее: из 500 запусков кода метаалгоритм обошёл среднее по 5 алгоритмам в 381 случае. В остальных случаях обычное усреднение было сильнее матаалгоритма.
По поводу библиотеки — это к её создателям.
Если будет вопрос по моей реализации — то это ко мне.
Тут много зависит от того, как Вы измеряете качество. Ну а как улучшить блендинг: об этом как раз эта заметка (усреднять блендинги, настраивать его параметры, использовать регрессионные метапризнаки и т.п.)
У меня такой вопрос: я сомневаюсь, что на мой вопрос можно ответить. Если так, то не отвечайте на него.
Сегодня реализовал два абзаца на Титанике. Я тоже решил написать авторскую реализацию стэкинга и блендинга (некоторые идея я подсмотрел у Александра Геннадьевича в его примере, но решил, что лучше всё сделать самому — так будет полезнее и интереснее)
Реализовал простейшую схему:
«Простейшая схема стекинга — блендинг (Blending): обучающую выборку делят на две части. На первой обучают базовые алгоритмы. Затем получают их ответы на второй части и на тестовой выборке. Понятно, что ответ каждого алгоритма можно рассматривать как новый признак (т.н. «метапризнак»). На метапризнаках второй части обучения настраивают метаалгоритм. Затем запускают его на метапризнаках теста и получают ответ».
И реализовал вот эту штуку:
«Самый большой недостаток блендинга (в описанной реализации) — деление обучающей выборки. Получается, что ни базовые алгоритмы, ни метаалгоритм не используют всего объёма обучения (каждый — только свой кусочек). Понятно, что для повышения качества надо усреднить несколько блендингов с разными разбиениями обучения».
Я заметил, что усреднение дало значительное улучшение результатов.
Простейшая схема: из ста запусков метаалгоритм показал себе лучше в 97 случаев, чем среднее по пяти алгоритмам. В трёх остальных случаях метаалгоритм был наравне или лучше самого лучшего алгоритма.
Усреднение нескольких блендингов: Метаалгоритм был лучше среднего в 48 случаях, чем среднее по пяти алгоритмов. В остальных случаях метаалгоритм был наравне или лучше самого лучшего алгоритма.
Мы видим огромное улучшение результатов усреднение по сравнению с простейшей схемой.
Вопрос (возможно, на него нельзя ответить — тогда не отвечайте): нельзя ли как-то проверить хитрым способом, а правильно ли я всё это реализовал? Вдруг где-то ошибся? Не существует ли неких хитрых приёмов для тестирования себя? Как-то устроить себе проверку? Я же мог допустить ошибку в любой строчке?
Кстати, не забывайте, что в блендинге есть ещё параметры, которые можно настраивать… например, отношение в котором Вы делите обучающую выборку.
К сожалению, каких-то 100%-ых способов проверки нет. В ML с этим вообще туго. Если задача плохо решается, то может быть
1) неверно выбрана модель алгоритмов
2) неверно её настроили
3) неправильно реализовали
4) задача в принципе плохо решается
Поэтому, в отличие от классического программирования, здесь если что-то не работает, то гораздо сложнее понять что.
И ещё хотел задать один вопрос: «Естественное обобщение стекинга — сделать его многоуровневым, т.е. ввести понятие мета-мета-признака (и мета-мета-алгоритма) и т.д. Опять же, лучше воздержаться от этого при решении реальных бизнес-задач, а в спортивном анализе данных так часто делают»
А почему в реальных бизнес-задачах так не делают? Возьмем транспорт: даже если мета-мета-признак даст улучшение всего лишь на 0,5 процента — это может сыграть огромную роль в некоторых ситуациях. Да, это сложнее, но может возникнуть такая ситуация, когда 0,5 процента — спасение человеческой жизни. На мой взгляд, любое улучшение результата — хорошо, а в некоторых случаях — невероятно важно.
Так почему же в реальных бизнес-задачах не пытаются выжать максимум из алгоритмов?
В реальных задачах всегда ищут компромисс между скоростью работы алгоритма (обучение + валидация) и его точностью.
Сложность начинает растить экспоненциально, то есть рост точности на 0,0001% увеличивает время обучения на 10% (условно).
Это да, но далеко не главная причина.
В 85% практических задач всё-таки скорость обучения не важна (важнее скорость работы — например, классификации).
Скажем, даём рекомендации в почтовых рассылках… ну путь они сутки считаются, всё равно мы спамим наших клиентов не чаще чем 1-2 раза в неделю.
Или, например, если мы детектируем болезнь по кардиограмме, да пусть хоть месяц обучаемся (это надо один раз сделать!) и день классифицирует — вот тут как раз важнее качество.
1. Задач, где именно потребность в высокой скорости применения аналитики ограничивает сложность, немного. HFT в трейдинге, антифрод в карточном процессинге, событийный маркетинг в ряде задач (например, если он дается по геолокации) и т.д..
2. Есть юридические причины, из-за которых ограничивается сложность. Требования регулятора (для того, чтобы затруднить попытки регуляторного арбитража или не допустить реализации оп.рисков в системных банках, которые могут пошатнуть всю финансовую систему), требования законодательства (борьба с дискриминацией, право на объяснение и т.д.) — с этим в России тоже мало кто сталкивается, это про очень большой бизнес, банки топ-10 или про работу в западных юрисдикциях, но именно они во многом и задают правила игры, хотя это не всегда очевидно.
3. Есть технические причины. Трудоемкость (или даже техническая невозможность) внедрения и трудоемкость регрессионного тестирования. Модель в виде объекта, а не скрипта, полученную с помощью некоторой библиотеки, невозможно использовать в среде, где эту библиотеку нельзя запустить. Разве что самостоятельно писать реализацию всех необходимых алгоритмов в этой среде, что не просто, недешево и т.д. Вызвать нужный метод или класс и побаловаться настройками и написать такой класс на C или Java это разный уровень компетенции, причем не только в машинке, но и в теории алгоритмов и теории оптимизации (SGD и прочие радости)
4. Есть бизнес соображения. Причем это не только интерпретируемость модели, сколько операционные риски (модельный риск, например). Главное правило инвестора: 100+100+100-100 = 0
Процентов, разумеется.
…
Вы правы, но на практике есть куча разных «НО», которые мешают сложным алгоритмам (не обязательно стекингу) существовать на практике
1) Есть люди, которые очень хотят понимать, что Вы делаете. Если Вы пишите сайт — то всем важен лишь результат. А если Вы пишите систему рекомендаций для интернет-магазина, то продуктовые менеджеры спрашивают «а как Вы рекомендуете?» И не все поймут заумные «матричные факторизации»… и не всегда дадут добро!
2) Причина связанная с п.1: люди бизнеса хотят влиять на работу алгоритма. Для этого нужны параметры, которые они могут» подкрутить». Скажем, коэффиент в линейной регрессии — это понятно что такое — его легко интерпретировать, объяснить человеку, и понять, как изменится решение… а вот какой-нибудь «процент разбиения обучения на части» в стекинге — объяснить сложнее и «крутить» вручную бессмысленно
3) На практике Вы должны быстро реагировать на неадекватную работу алгоритма. Если почему-то вдруг(!) не работает линейная регрессия, то легко понять почему. А вот если перестал показывать высокое качество стекинг…
4) Пожалуй главное. Не имеет смысл хорошо минимизировать стандартную ошибку в задачах классификации/регрессии. Дело в том, что в бизнесе Важны деньги, лояльность и т.п. Это всё сложно перевести в математическую формулу. Поэтому настраивая какой-то классификатор Вы решаете не реальную задачу, а лишь её возможную (неточную!) интерпретацию!
Ну можно ещё писать и писать на эту тему…
«Второй способ борьбы за использование всей обучающей выборки — реализация классического стекинга. Ясно, что совсем не делить обучение на подвыборки (т.е. обучить базовые алгоритмы на всей обучающей выборке и потом для всей выборки построить метапризнаки) нельзя: будет переобучение, поскольку в каждом метапризнаке будет «зашита» информация о значении целевого вектора (чтобы понять, представьте, что один из базовых алгоритмов — ближайший сосед). Поэтому выборку разбивают на части (фолды), затем последовательно перебирая фолды обучают базовые алгоритмы на всех фолдах, кроме одного, а на оставшемся получают ответы базовых алгоритмов и трактуют их как значения соответствующих признаков на этом фолде. Для получения метапризнаков объектов тестовой выборки базовые алгоритмы обучают на всей обучающей выборке и берут их ответы на тестовой».
Я не уверен, что на сто процентов понял Ваш текст правильно. Позвольте снова вернемся к Титанику, чтобы лучше это представить.
Пусть есть тренировочная выборка: Маша, Катя, Оля, Вася, Таня, Борис
Разобьем тренировочную выборку на три фолда:
F1 — Маша и Катя
F2 — Оля и Вася
F3 — Таня и Борис
Первый случай:
тренируем базовые алгоритмы (пусть их будет три: A1, A2, A3) на F1 и F2, то есть на табличке, в которой находятся Маша, Катя, Оля, Вася.
После тренировки смотрим, какой прогноз дадут наши алгоритмы на F3, то есть мы получим нечто следующее:
Таня — 110
Борис — 010
Второй случай:
тренируем базовые алгоритмы (те же A1, A2, A3) на F1 и F3. После тренировки смотрим, какой прогноз дадут наши алгоритмы на F2, то есть получаем нечто следующее:
Оля — 101
Вася — 001
Аналогично третий случай: мы получим табличку из нулей и единиц для Маши и Кати:
Маша — 110
Катя — 111
Теперь наш метапризнак — объединение трех этих маленьких табличек (по крайней мере, уважаемый Александр Геннадьевич, это изображено на Вашем рисунке 3)
Маша 110
Катя 111
Оля 101
Вася 001
Таня 110
Борис 010
Наша следующая цель — натренировать метаалгоритм B. На вход этому алгоритму мы подаем табличку выше, а на выход — реальные значения о том, погибли эти люди на Титанике или нет.
Тренируем этот метаалгоритм B.
Далее нам нужно получить метапризнаки на тестовой выборки. Мы тренируем алгоритмы A1, A2, A3 на всей обучающей выборке (то есть на Маше, Кате, Оле, Васи, Тани, Борис вместе, без разбиения на фолды). Теперь подаем натренированным алгоритмам значения на тестовой выборке, и получаем их ответы. Так мы находим метапризнаки тестовой выборке.
Наш последний шаг — запустить метаалгоритм B, подав ему на вход метапризнаки тестовой выборки, и получить предсказания, выжил ли пассажир на тестовой выборке или умер.
Правильно ли я Вас понял?
«Здесь тоже желательно реализовывать несколько разных разбиений на фолды и затем усреднить соответствующие метапризнаки (или ответы стекингов!)».
То есть мы, предположим:
1. Разбиваем на 3 фолда, на 4, на 5, на 6, на 7, на 9 и так далее (всего у нас l фолдов)
При разбиении на 3 фолда получаем предсказание Y1 для тестовой выборки.
При разбиении на 4 фолда получаем предсказание Y2 для тестовой выборки.
При разбиении на 5 фолдов получаем Y3
….
При разбиении на n фолдов получаем Ym.
Теперь считаем Y3+…+YM и делим полученную сумму (для каждого человека из тестовой выборки) на l. Для Титаника — сравниваем с порогом в 0,5, и в итоге находим ответ.
Правильно ли я понял Вашу мысль в этих двух абзацах?
До вопроса «Правильно ли я Вас понял? » — Вы всё верно поняли.
Что касается «несколько разных разбиений на фолды» — не обязательно делать на разное число фолдов. Число фолдов часто выбирается так: достаточно много, но чтобы считалось за приемлемое время. Можно такие разбиения на фолды:
(Маша и Катя), (Оля и Вася), (Таня и Борис)
(Маша и Оля), (Таня и Вася), (Катя и Борис)
(Борис и Оля), (Таня и Маша), (Катя и Вася)
и т.д.
Получаем ответ на тесте для каждого разбиения, потом берём среднее всех ответов.
Жаль что увидел вашу статью в последний день соревнования ML Bootcamp, применил бы знания:)
вопреки мнению Романа все изложено очень понятно, а схемы вообще жгут: «вместо тысячи слов». ПС: я совсем новичок в МО.
Вопрос у меня следующий: когда мы получаем мета-признаки для тестовой выборки, есть два подхода:
1) усреднить предсказания моделей, обученных на фолдах трейна (то есть использовать ровно те же модели, что используются для получения «кусочков» мета-трейна)
или
2) мета-признаки теста получаем из модели, обученной на всем трейне, а не на фолдах.
В вашей статье описан только второй.
В обоих случаях есть проблема «разных мета-признаков на тесте и трейне», но где по вашему мнению эта разница больше? Нет ли в первом способе утечки?
Спасибо за отзыв. Хороший вопрос. Сложно сказать, где разница больше, но в первом способе есть ещё один недостаток… усредняя мы получаем значения, которые могут быть не типичны для этого метапризнака. Например, у нас бинарный (или почти бинарный — все значения близки к 0 или 1) метапризнак, но тогда при усреднении на тесте по (1) он может принять какое-то небинарное значение, 0.75 например. Поэтому в схеме (1) надо тогда и метапризнаки обучения усреднять (по разным разбиениям на фолды).
хм… я имел в виду метапризнаки в виде вероятностей, а не 0-1
кстати вот тоже хороший вопрос — что лучше? если задача классификации.
по идее вероятности несут больше информации.
Я понял, я для примера привёл: что усреднение может портить свойства признаков. Тут да, надо вероятности использовать.
Очень хорошая и доступная статья получилась, спасибо! (хоть я и относительно новичок — но вроде всё понял)
А я до конца не всё понял. Точнее не стал до конца во всём разбираться. Написал реализацию фолдов, и пока остановился. В чём я ещё до конца не разобрался — как правильно использовать библиотеку brew и heamy. Brew у меня выдаёт ошибки. А вот heamy — нужно разобрать готовый пример, который идет в комплекте. Я пока этого не сделал.
Зато за последние несколько дней написал программу в Linux: у меня есть веб-камера. Когда я подхожу к компьютеру, моя веб-камера меня видит, и раздается звук: «Здравствуйте». Когда я отхожу от неё, она говорит: «До свидания». Использовал простейшие методы машинного обучения: простой Случайный лес — точность в 98 процентов.
Теперь хочу научить её понимать, когда я отрываю холодильник, когда захожу на кухню и так далее. Тут мне нужно будет разбираться в Tensor FLow, потому что, вроде бы, именно эту штуку используют в серьёзных вещах.
Так вот, моё пожелание на будущую тему — что-то написать о TensorFlow. Я сейчас разбираю одним пример на Kaggle, чтобы самому научить машину точнее меня распознавать, распознавать моих родственников, общаться со мной, но всё равно лишняя статья, тем более на русском языке, мне будет полезна.
Александр, добрый день!
Спасибо за вашу статью, действительно, самое прозрачное описание стэкинга, которое встречал на русском языке. Буду вашу статью рекомендовать коллегам, как первый гайд по теме.
Хотелось бы очень ваше мнение услышать на тему того, как же всё-таки выбрать метаалгоритм? Может приведете top-5, которые давали лучшие результаты или bottom-5 безнадежных вариантов, как Ridge с метрикой Logloss?
Спасибо!
Здравствуйте, Михаил! На самом деле, это вопрос примерно сопоставим с вопросом «а как выбрать алгоритм для решения задачи?» Основной совет я дал: надо ориентироваться на функционал качества. А дальше — надо экспериментировать… мне кажется, тут нет каких-то 100% советов. Потом, многое зависит от базовых алгоритмов. Например, SVM хорошо работает в однородных признаковых пространствах (все признаки одной природы и в одном масштабе). Если ответы базовых алгоритмов таковы, то SVM подойдёт в качестве мета-алгоритма. В противном случае — он «только всё испортит».
За последние несколько дней написал ещё одну программу с машинным обучением. Без TensorFlow, без метаалгоритмов. Банальный случайный лес с параметрами по умолчанию. Фантастика, но уже в более сложной задачей всё работает. Программа приносит мне реальную пользу.
Поражает, что машинное обучение сейчас так легко использовать (на простом уровне, я сейчас не беру соревнования на Кагле и прочее, там всё сложнее, и мне многое там не понятно). Но поражает, какие вещи можно делать с самыми простыми алгоритмами (то есть всё элементарно, а программа приносит пользу).
На простом уровне это стало как лампочка. Включил, нажал кнопку — всё работает. Я под впечатлением того, какие сложные вещи можно решать настолько простыми методами.
Я раньше и не мог поверить, что интересные практические задачи можно решать так просто, так быстро (опять же, тут речь идёт о простых вещах, я не говорю о сложных задачах — там нужно много учиться). Я под сильным впечатлением.
Ну только «банальный» случайный лес – это вовсе не простой алгоритм. Это достижение человечества в том, что его можно взять и применить почти что «из коробки». А так в основе очень много математики, и многое еще про случайный лес неизвестно.
Согласен. Но здесь есть одна проблема. Для себя можно написать всё на коленке. Но всё становится сложнее, если выпустить эту программу для других людей. У всех разные веб-камеры. У всех разное расстояние от веб-камер до человека. У всех всё по-разному. Для себя можно написать полезную программу, скажем, из 1000 снимков (база — 1000 снимков, и программа уже приносит тебе пользу).
Если делать программу не только для себя, а, скажем, всех остальных людей, то всё становится сложнее в плане сбора данных.
Или я хочу ещё написать одну программа, которая может приносить пользу в жизни. Тоже можно будет сделать для себя на коленке, и я собираюсь это в ближайшие дни сделать, и всё будет работать, а вот если говорить о других людях: опять, ситуаций может быть очень много, и здесь начинаются проблемы со сбором данных, потому что у меня нет так много знакомых, чтобы я мог на них собрать данных, а их нужно очень много.
То есть я вижу следующую ситуацию: для себя писать очень просто (я говорю о своих простых программках, я не говорю сейчас о сложных ситуациях или о соревнованиях на Kaggle), но возникают проблемы с данными, когда мы программу хотим делать не только для себя, но и для других, чтобы результаты были адекватными.
Вот какую проблему я вижу в настоящий момент.
Я согласен с Вами, Yury Kashnitsky, что случайный лес — достижение человечества. На мой взгляд, самое важное в машинном обучении — люди, которые делают машины быстрее (на уровне железа, без них ничего бы не было). На втором месте — люди, придумывают новые алгоритмы вроде Случайного леса и прочих (без них тоже ничего бы не было).
Добрый день.
Дайте, пожалуйста, ссылку на Людмилу Кунцеву:
Людмила Кунцева ссылается как-то на брошюрку за 90 копеек (!), в которой многие из таких подходов описаны.
Это к Юрию вопрос…
Ну, наверное, достижение человечества – это слишком общая фраза. Хотя идеи бэггинга и использования рандомизации высказывались ранее (Диттерих, Кляйнберг, Хо и др.), первым, кто это систематизировал и реализовал в виде случайного леса был Лео Брейман. Человек, кстати, беспримерного мужества и редкой интуиции. Одной из целей создания RF было улучшение прогнозирования онкологических заболеваний и повышение эффективности лечения. Умер от рака, работал до последних дней. В последние 5 лет ему тяжело болеющему помогала Адель Катлер, решала задачи визуализации леса, занималась unsupervised RF, написала программный код на FORTRAN, а ее друг Энди Лив реализовал его в R. Брейман оставил большое наследие идей, Ишваран предложил случайный лес выживаемости, Мэлли – вероятностный лес, далее ими обоими была предложена идея синтетического случайного леса, попытались реализовать незаконченную идею Бреймана о варьировании nodesize при построении деревьев, на мой взгляд, получилось громоздко с т.з. соотношения размера получаемых моделей и качества.
у меня такой вопрос в виде оффтопа к этому замечательному блогу. Скажем, у меня есть вопрос по Keras: я на Кагле увидел, как его используют, решил применить к Титанику — что-то не работает. Конечно, лучше мне пройти курс на Курсере по Нейронным сетям и прочитать книгу по нейронным сетям, а также почитать побольше о TensorFlow — я стараюсь каждый день немного уделять этому времени, но ждать, пока я всё это сделаю и доберусь до Keras — это долго. Хочется применять прямо сейчас.
В общем, я задал свой вопрос на http://stackoverflow.com — пока мне никто не ответил (уточняющие вопросы — это не ответ).
А какие существуют хорошие места в интернете, где отвечают на вопросы по машинному обучению для новичков помимо stackoverflow.com? Какие вы советуете?
Отличная статья! Всё понятно! Читается на одном дыхании! Спасибо!
Отличная статья!
хотелось бы узнать мнение автора по поводу усреднения при двухклассовй классификации какое усреднее он считает будет работать лучше арифметическое или геометрическое?
Это зависит от функционала качества. Обычно при log_loss среднее геометрическое работает чуть получше (если за 1 обозначен более редкий класс). Но вообще, надо экспериментировать. Благо, перебрать разные способы усреднения совсем не трудоёмко.
Здравствуйте Александр ! Спасибо за интересную статью. Я часто использую стекинг. В одном из соревнований на Kaggle (Bimbo) наша команда победила используя такой подход. Меня интересует регуляризация с добавлением шума. Есть ли исследования в этой области ? Почему именно гаусовый шум добавляют ? Есть ли смысл в распределениях шума с толстыми хвостами ? Я также пробовал делать стекинг с помощью Байесовской линейной регрессии (https://arxiv.org/pdf/1612.05740.pdf). Я вижу смысл в том, что целевую переменную в таком подходе мы можем представить через распределение, например, Стьюдента и тем самым учитывать роль выбросов или экстремальных значений.
Здравствуйте! Честно говоря, я особо не искал, есть ли здесь какие-то исследования. Просто это приём, который иногда используют. Например, здесь https://www.slideshare.net/OwenZhang2/tips-for-data-science-competitions на слайде 26 на шум умножают, чтобы не было переобучения при кодировании категориальных признаков с помощью целевого. Кстати, я участвовал в соревновании, в котором Оуэн так кодировал признаки, ему удалось с помощью кодировки добиться высокого качества от случайного леса. Я специально возился тогда с этой моделью, у меня результат был намного хуже. Но иногда этот приём работает, а иногда нет… Мне кажется, от выбора распределения там не особо много зависит.
Спасибо !
Богдан, подскажите, пожалуйста, каким образом выполняется представление целевой переменной через распределение Стьюдента? Очень заинтересовала ваша идея!
Статья замечательная, спасибо! Испытал некоторую боль при чтении о «переизобретении начинающими» 🙂 Не понял только, почему нельзя вот так:
alg1: X -> y1, score(y, y1) -> max,
alg2: X -> y2, score(y, y2) -> max,
meta: (y1, y2) -> y3, score(y, y3) -> max,
причем X,y1,y2,y3 — одно разбиение на train/test (именно вот это смущает).
Я правильно понял, что Вы предлагаете следующее: есть обучающая и контрольная выборки, на всём обучении Вы настраиваете базовые модели, потом на их ответах (на метапризнаках) настраиваете мета-алгоритм (используются опять метки обучающей выборки).
Да. То есть верные метки используются для обучения и контроля во всех алгоритмах.
Спасибо большое за замечательную статью!
Не могли бы Вы подсказать, чем отличаются базовые алгоритмы одинаковой природы (например на рис.4: 9 rf и 3 gbm) и почему не просто по одному rf и gbm?
Пожалуйста.
Для определённости возьмём GBM. У этой модели есть параметры, как раз и определяющие природу, — ограничения сложности деревьев. В зависимости от реализации это м.б. глубина деревьев, число листьев, максимальное число объектов в листе и т.д.
Разные GBM — это бустинги на деревьями разной сложности, например, над деревьями разной глубины.
Спасибо! Интересно, насколько это лучше, чем использование, например, rf и gbm с уже подобранными оптимальными параметрами
Можете сами поэкспериментировать…
[…] Cтекинг (Stacking) и блендинг (Blending) (7731 просмотр) […]
Здравствуйте. Есть ли работы, в которых исследуется вопрос добавления нормального шума к данным и связь этого факта с регуляризацией? Или просто исследования на эту тему. Может кто знает?
Ну тут много чего есть… начиная от
Нажмите для доступа к bishop-tikhonov-nc-95.pdf
заканчивая
Нажмите для доступа к 1612.01490.pdf
«В отличие от бустинга и традиционного бэгинга при стекинге можно (и нужно!) использовать алгоритмы разной природы (например, гребневую регрессию вместе со случайным лесом).»
Добрый вечер. Опасаюсь нарваться на некропостинг, но некоторое время размышлял о том, почему не использовать для бустинга разнородные алгоритмы? Не знакомы ли вам материалы, в которых можно почитать об этом или обосновывается бессмысленность идеи?
Здравствуйте! Ваша идея очень разумная. Я не знаю и сходу не нашёл её реализаций/опровержений. Скорее всего, она может выстрелить в некоторых специфических случаях. Но для большинства задач, я думаю, она не даст какого-то прироста в качестве. Есть несколько сложностей в её реализации… 1) какие алгоритмы бустить? Сейчас единственное эффективное применение бустинга — над деревьями: и по соображениям скорости, и по фактическим результатам качества. 2) как организовывать смену моделей, чтобы это имело смысл? (всегда же можно взять бустинги над разными моделями, а потом их сблендить — как сделать так, чтобы результат был лучше такой примитивной тактики) 3) как сделать модель удобную для настройки? (много разнородных моделей означает много параметров, плюс параметры самого бустинга, получается слишком большое пространство для оптимизации)
Александр Геннадьевич, спасибо за статью! Позвольте задать несколько вопросов:
1) Откуда берется тестовая выборка? И для чего она испльзуется? Идет ли речь о подмножестве исходных данных? Или о данных, которые поступают на вход для получения прогнозируемых значений целевого атрибута? Если первое — то используются ли эти данные просто для финальной оценки качества модели или результат на тестовой выборке может повлиять на коэффициенты модели для метаалгоритма? Если второе — то почему это многострочная выборка, а не отдельный одиночный объект (как, часто, это бывает)?
2) Несовсем понял логику вот этого этапа в классическом стекинге: «Для получения метапризнаков объектов тестовой выборки базовые алгоритмы обучают на всей обучающей выборке и берут их ответы на тестовой.» Почему мы не можем использовать в качестве метапризнаков результаты моделей, обученных на отдельных фолдах, полученные для целиковой тестовой выборки? Зачем тогда мы обучаем базовые алгоритмы на отдельных фолдах? Или при переходе к тестовой выборке модель метаалгоритма остается неизменной (такой же, какую мы получили при обучении на отдельных фолдах?
Буду очень признателен за объяснение!
И, лично мне, очень не хватает пошагового описания:
1) Делим исходные данные на k фолдов. (Причем, как мы делим: стараемся ли мы сохранить в фолдах статистический характер распределения данных из исходного набора данных?)
2) Для каждого из (k-1) фолдов выполняем обучение базовых алгоритмов.
И т.д.
Здравствуйте!
1) Откуда берется тестовая выборка?
Здесь тестовые объекты — те, которые нам надо классифицировать. Они могут быть сразу не даны.
2) то почему это многострочная выборка, а не отдельный одиночный объект (как, часто, это бывает)?
На самом деле, это не принципиально. Здесь мы никак не используем тестовую выборку и тот факт, что там несколько объектов. Просто показываем, как алгоритм будет на них работать.
3) Почему мы не можем использовать в качестве метапризнаков результаты моделей, обученных на отдельных фолдах, полученные для целиковой тестовой выборки?
Так тоже делают. Тут даже был комментарий по этому поводу.
Более того, такой способ даже более популярный.
Но у него есть недостатки.
*) вам придётся усреднять метапризнаки обучения, полученные алгоритмами, настроенными на разных фолдах. А это немного ломает их смысл. Например, у Вас есть алгоритм, который выдаёт 0 или 1, после усреднения он будет выдавать что-то между этими числами… метаалгоритм может такого не ожидать
*) чуть неудобнее реализация в стиле scikit-learn. Если Вы сами будете реализовывать класс «Стекинг», то Вам придётся хранить все эти базовые алгоритмы для всех фолдов. В моём варианте — только базовые и мета-алгоритм.
4) Зачем тогда мы обучаем базовые алгоритмы на отдельных фолдах?
Их обучают, чтобы натренировать мета-алгоритм. Он тренируется на метапризнаках обучающей выборки. Чтобы в ней не было утечки — делают k-fold-разбиение.
5) Или при переходе к тестовой выборке модель метаалгоритма остается неизменной (такой же, какую мы получили при обучении на отдельных фолдах?
Да, только метаалгоритм мы обучаем на метапризнаках всей обучающей выборки (просто эти векторы-признаков состоят их кусочков, которые получены с помощью базовых алгоритмов, обученных с K-fold-схемой).
6) стараемся ли мы сохранить в фолдах статистический характер распределения данных из исходного набора данных?
Это как бы общий вопрос правильной реализации k-fold-разбиения. Естественно, лучше сохранять пропорцию классов.
Спасибо за пожелания, я скоро буду переписывать этот текст для книги. Надеюсь, там будет понятнее.
Спасибо огромное!
Хотел еще поделиться несколькими полезными видео, которые мне удалось найти по теме стекинга:
1) Blending
https://ru.coursera.org/lecture/competitive-data-science/stacking-Qdtt6
2) StackNet (вариант реализации многослойного стекинга)
https://ru.coursera.org/lecture/competitive-data-science/stacknet-s8RLi
3) Полезные советы по реализации стекинга
https://ru.coursera.org/lecture/competitive-data-science/ensembling-tips-and-tricks-XqLc1
Статья супер, продолжайте в том же духе!
Спасибо за статью. Новичок в DS но всё в целом понятно. Комментарии не менее ценные.
Скажите пожалуйста.
При переносе вашей имплементации стекингда для задач классификации (а не регрессинга) ваш код в целом подойдет? Большие нужны изменения?
Здравствуйте! Извините, что не сразу отвечаю. Да напрямую переносится, вроде, даже изменений не нужно. Но базовые алгоритмы лучше брать либо регрессионными, либо классификаторы c predict_proba.
Извините и еще один вопрос. А посоветуйте пожалуйста базовые алгоритмы для бинарной классификации?
Если выполнить такой код, то получите список алгоритмов классификации в scikit-learn
from sklearn.utils.testing import all_estimators
estimators = all_estimators()
for name, class_ in estimators:
if hasattr(class_, ‘predict_proba’):
print(name)
Спасибо за статью. Интересует пункт «Деформация признаков». Мне кажется, что он не очень раскрыт. Не очень понятна цель деформации признаков, её возможности и пр. И если есть материалы на эту тему, то не ясно как их искать, т.к. в примерно такой терминологии (и похожей) ничего не находится. Подскажите, пожалуйста, куда копать?
И обычно считается полезным сокращение признакового пространства, а в вашем примере получается его увеличение.
«считается полезным сокращение признакового пространства»
Это слишком общая фраза, которая на вид не вызывает возражений, но на самом деле, надо понимать, что за ней стоит… Этот как «нельзя пить некипячёную воду, в ней могут быть бактерии» — всё верно, но какой смысл говорить её, например, умирающему от жажды путнику?
Признаковое пространство увеличивается много где:
1) при полиномиальной регрессии
2) при OHE-кодировании (здесь мы вообще, заменяем один признак на сотню)
3) при любом использовании специфических признаков типа «дата», «координаты» и т.п. (мы добавляем признаки «день недели», «праздник ли», «год» и т.п.)
4) итеративно по слоям в нейросетях (но тут можно поспорить…)
Сокращение признакового пространства произодят для
1) устранения избыточности (например, дубликаты признаков приводят к переобучению при использовании линейной регрессии)
2) устранения шума (исключение из задачи признаков, от которых не зависит решение)
3) улучшения настройки и интерпретации модели (почти одинаковые признаки могут приводить к нежелательным эффектам в Random Subspaces)
В стекинге парадоксальная ситуация — тут заведомо метапризнаки похожи (т.к. они все похожи на целевой). Тем не менее, мы их изначально не сокращаем. Да и вообще, во всех ансамблях, это не делается (в том же случайном лесе, например, там каждый метапризнак порождается отдельным деревом).
Поэтому, скажем, взять попарное произведение каких-то метапризнаков не кажется безумной идеей (по крайней мере, это произведение будет слабее коррелировать с другими метапризнаками).
Но ещё раз напомню, деформация — это лишь мой совет. Не всегда она эффективна и оправдана на практике. А попробовать нетрудно: несколько строчек кода.
Здравствуйте! Скажем так, это совет. Я указал то, что сам делаю на практике. Правда, не указал точно, как именно я деформирую признаковое пространство. Но куда копать ясно… в feature generation/engeneering. Я указал, что при стекинге, получившееся пространство метапризнаков считают окончательным, а можно же его улучшить, в том числе стандартными приёмами улучшения признаковых пространств.
Большое спасибо за ответы! Почитаю, попробую)
А каким образом лучше сделать стекинг, если возможны такие наблюдения, для которых одна из моделей не может предсказать исследуемый показатель (напр, нет набора данных, который использовался в этой модели; возникла ошибка при передаче оценки модели и пр.)?
Это же просто соответствует тому, что в метапризнаках будут пропуски… тогда делать все как обычно в задачах с пропусками.
[…] стекинг подробно смотрите здесь. При стекинге мы честно строим мета-алгоритм в виде […]
«Иногда здорово срабатывают идеи настройки не на целевой признак, а, например, на разницу между каким-то признаком и целевым»
Интересная идея — это вы имеете ввиду, что мы меняем на трейне вместо таргета разницу между ним и лучшим признаком и потом используем предсказанные значения, чтобы исправить этот самый признак?
Да, типа того. Только не обязательно использовать лучший признак… можно использовать группу признаков или все, если их немного.
Спасибо за оперативный ответ)
А как можно использовать группу признаков? И стоит ли убирать этот признак, который мы исправляем из трейна?
В стекинге же много метапризнаков. Вы можете одну и ту же базовую модель обучать на разные целевые признаки — разности исходного и каждого признака из группы. Сами признаки можно не убирать, но есть опасность переобучения. Главное — грамотно реализовать эту идею.
Понял, спасибо!
Здравствуйте Александр!
Спасибо Вам за хорошую статью в которой достаточно полезной информации для восприятия и ознакомления со стекингом! Так же обратил внимание на Вашу авторскую реализацию стекинга и мне захотелось сравнить ее точность с другими реализациями, только вот при попытке подключить к вашей реализации наборы данных (iris, wine, digits) возникает ошибка связанная функцией roc_auc_score, а именно «multi_class must be in (‘ovo’, ‘ovr’)»
Не могли бы Вы объяснить как возможно исправить данную проблему или возможно как правильно подключать к Вашей реализации различные наборы данных?
Спасибо за ответ!
У меня реализация для бинарных задач классификации, поэтому на перечисленных датасетах не удастся напрямую сравнить. У Вас в ошибке подсказка, как можно поступить — написать ещё оболочку, которая будет решать многоклассовую задачу.
Здравствуйте! Спасибо большое во первых за статью, во вторых за понятный подробный ноутбук на гите! У меня один вопрос — почему в задаче классификации Вы используете регрессоры?
Ну в качестве мета-алгоритмов можно использовать что угодно. Если классификаторы, то надо получать признаки с помощью predict_proba. Значения признаков должны быть довольно разнообразными. Я часто использую регрессоры.
Добрый день,
В моих данных помимо основных разнородных фич (~40 штук) есть столбец со слегка «мусорными» текстовыми данными. Хочется с помощью PyTorch обучить нейронку на этом стобце и подать ее ответы в общий алгоритм GB с остальными фичами. Боюсь, что нарушаю основное правило: при обучении нейронки буду «подглядывать в ответы». Делать полномасштабные блендинг / стекинг из- за этого одного «мусорного» стобца не имеет смысла: больше потеряю по основым фичам на уменьшении выборки / усреднениях соответственно. Как лучше поступить в этом случае?
Если это тексты, то воспользуйтесь Text Embeddings.
Спасибо за ответ!
Но у меня вопрос не столько о способе обработки текста, сколько о том, как внедрить метапризнак, полученный обученнием на ответах (!!!), в общую модель, чтобы не было утечки.